OBJECTIVE
The aim of the project is to create an intelligent pre-screening system based on BIG DATA architectures for the control of air transport passengers with the aim of increasing anti-terrorism security levels.
The system will be based on what is known as a Passenger Name Record, often abbreviated as PNR.
PNRs are compiled by travel agencies, air carriers and tour operators, contain information such as medical conditions and disabilities, meal preferences, means of payment, but also work address, email, IP address if you book online and personal information of emergency contacts.
This information is stored in a BIG DATA (Hadoop) architecture that is able to analyze it through Machine Learning algorithms using behavioral models, appropriately engineered, which analyze PNR with data archives, black-lists made available by the government agencies and Open Source Intelligence (OSINT) available on the network (websites, blogs, social networks, media, search engines, etc.).
These processing made reliable and efficient thanks to the distributed computing architecture characteristic of the Hadoop architecture, allow to assign a “risk score” of terrorism to the person in real time.
This classification must then be communicated to the airlines to subject the suspect to extended baggage and/or personal checks, and to contact law enforcement if necessary.
It will also allow to have a series of investigation tools with high levels of analysis, since data analytics tools will be created that can identify relationships through the extraction of useful information made available, such as places, organizations and people.
In a conventional passenger screening workflow, government agencies have little time to react to incoming data from the moment a passenger manifest is generated when the traveler reaches a border checkpoint.
This platform makes it possible to make this process more efficient, since you can start as soon as the passenger buys the ticket, and also allows:
- Imports of all advanced passenger data (API).
- Automatically controls all passengers.
- Manually check less than 1% of travelers.
- Catch terrorists, smuggling, missing persons, excess visas, etc.
- Promote legitimate travel.
- Speed up the screening process.
- Makes global travel safer for everyone.
ARCHITECTURE
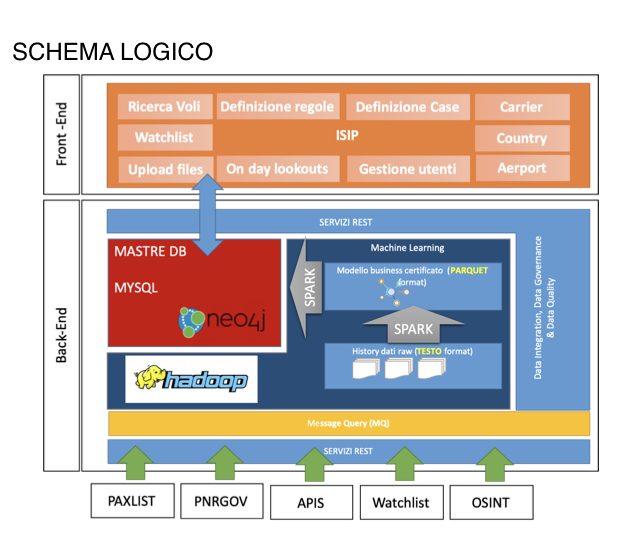
The logical platform architecture should include the following architectural layers:
- Distributed storage system, based on Hadoop, relational DB and Nosql
- Machine Learning algorithms
- Streaming Processing
- Use via Web platform – (Angular, java)
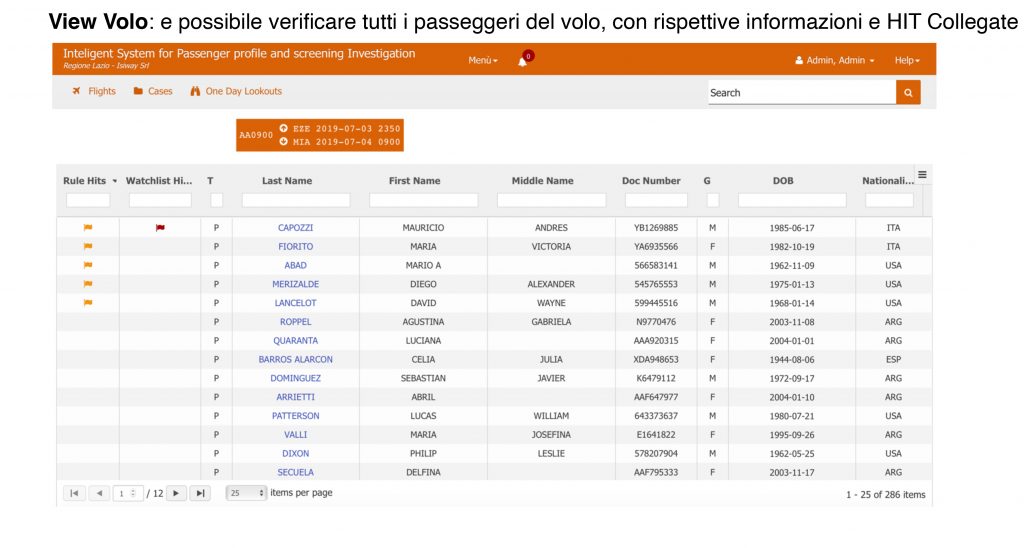
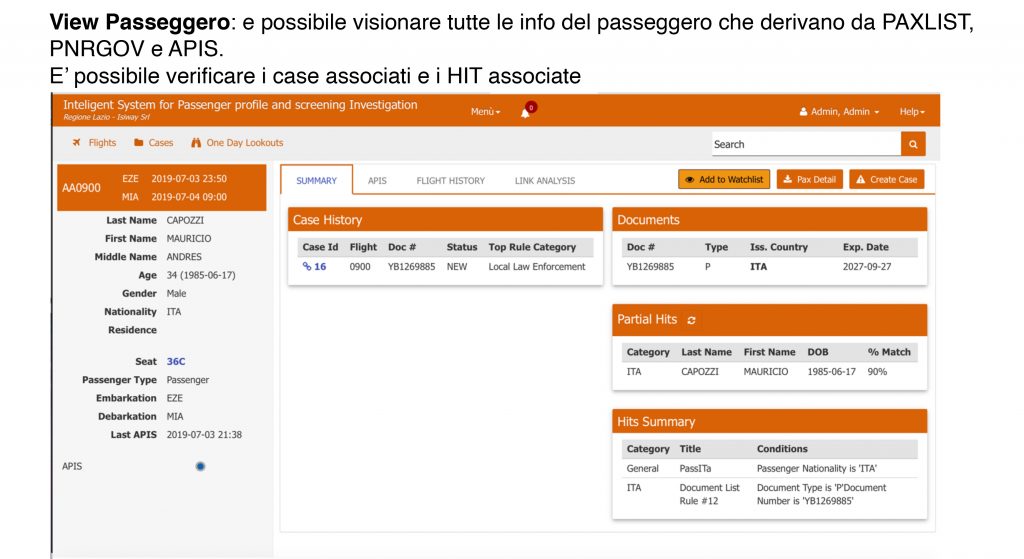
ISIP analyses data provided by airline departure control systems (APIs) and reservation systems (PNR). Respectively, these messages are compliant with WCO UN / EDIFACT PAXLST and PNRGOV formats.
- UN / EDIFACT PAXLST 02B and later versions
- PNRGOV 11.1 and later versions
ISPI PLATFORM
the Intelligent system for passenger profile and screening investigation.
(ISIP) is a web application to improve border security.
It allows government agencies to automate the identification of high-risk air travellers prior to their planned travel.
The United Nations has called on members to use Advance Passenger Information (API) and Passenger Name Record (PNR) data to prevent the movement of high-risk travellers.
The World Customs Organization (WCO) has partnered with U.S. Customs and Border Protection (US-CBP) because of the shared belief that every border security agency should have access to the latest tools. US-CBP has made this repository available to the WCO to facilitate deployment for its member states.
BACK-END PLATFORM
The Back-end platform consists of the following elements:
1) Hadoop infrastructure (Cloudera) for machine learning algorithms:
- a) Detection of Unusual Patterns from PAXLIST, PNRGOV and APIS
- b) Outlier identification through Neural Networks and LOF
2) Data persistence for front-end platform management
- a) based on Maria DB
- b) Hadoop (Cloudera) for machine learning training and execution
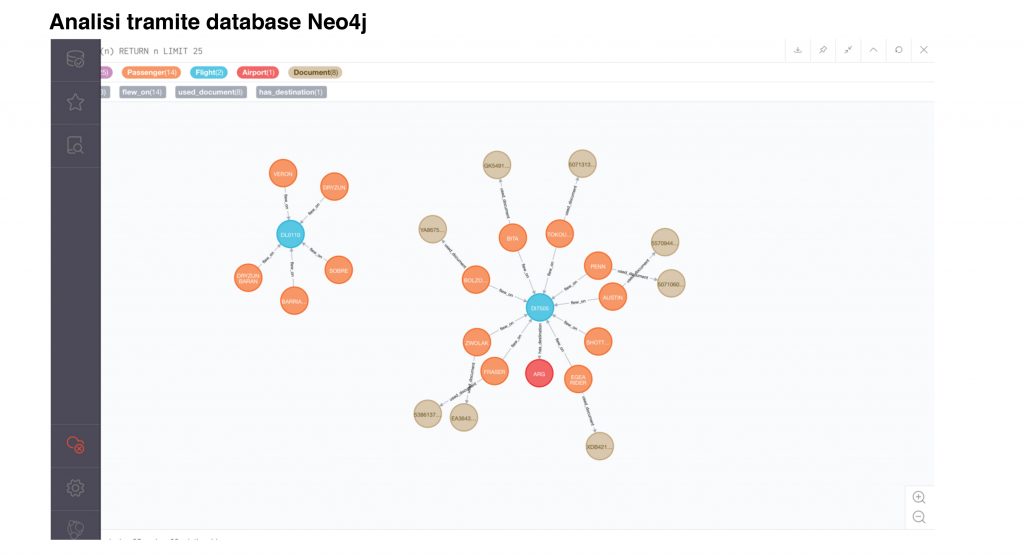
- c) Neo4j for analysis and Hit identification through Graph rules
3) Processing interfaces
(a) PAXLIST, PNRGOV and APIS parser services
- b) QM services for real-time data analysis and loading
- c) ETL (Pentaho) procedures for loading data into Hadoop and Neo4j
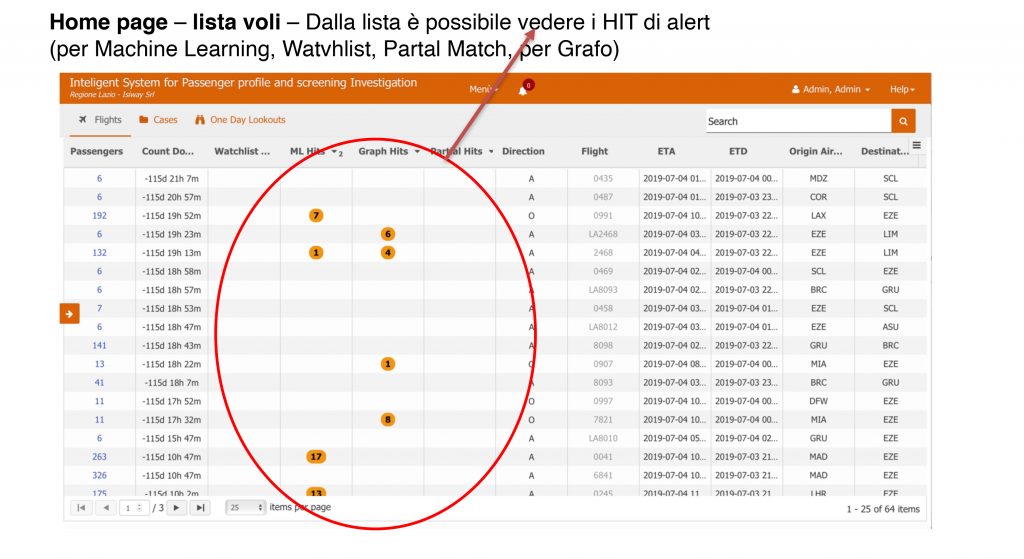
- d) HIT processing services (for Machine learning, for Graph, for Match Jaro-Winkler, for rules and for Watchlist
4) Technology: Java 8, Apache Tomcat 8, MariaDB 10.0 Stable, Apache ActiveMQ and Angular
BACK-END ELABORATION PROCESS
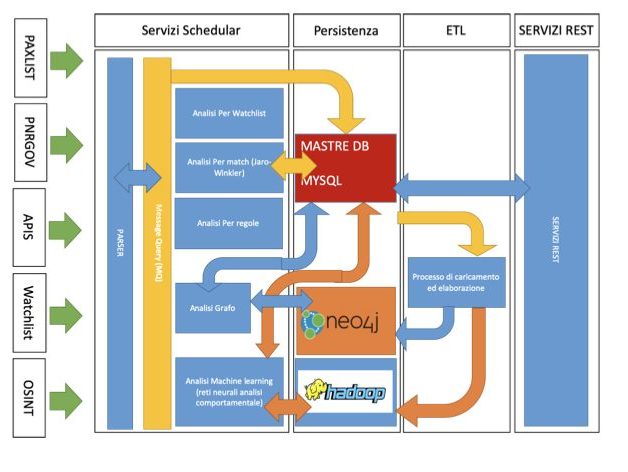
The back-end processes:
1) Parser Service
This Background process listens in a folder on the server, where it is tasked with processing PAXLIST, PNRGOV and APIS files and feeding a MQ queue.
2) Processing scheduling service: from the MQ queue there are the following trending processes
- a) Process of persistence towards the DB
- b) Watchlist HIT Process
- c) HIT process for Match Jaro-Winkler
- d) HIT Process by Rules
- e) HIT Process for Graph
- f) HIT process for Machine learning (neural networks) – Outlier identification through Neural Networks and LOF
3) ETL processes (pentaho)
- a) Loading data to Neo4j
- b) Uploading data to Hadoop
4) REST services to support the Front-End
BACK-END PLATFORM