
In recent years, the research and development activity carried out by Humanativa has been aimed at the theme of Machine Learning through the experimentation of different Deep Learning models. In 2022 our goal is to strengthen this competence, a strategic choice supported by observers and analysts worldwide, who agree that this technology will be strongly used in the coming years, especially with the arrival of European PNRR funds. The series of articles that we will dedicate to this technology aims not only to analyze the technical aspects but also to share the projects that Humanativa is starting in this area.
Human Neural Networks and Artificial Neural Networks
The mechanism of operation of human Neural Networks is now used as a model to address multiple applications of Artificial Intelligence, such as image recognition, voice recognition, biometric applications, autonomous driving and simulators of various kinds.
But how do Neural Networks work?
Neurons, the brain’s fundamental cells, are composed of a part of a nucleus surrounded by the body of the neuron, also called soma. The nucleus is connected to other neurons through two types of branches: dendrites([1]), which collect inputs, and axons([2]), which emit outputs.
Synapses act as connectors between axons and dendrites, allowing information to pass between one neuron and another.
Through electrochemical processes, the synapse sends pulses along its axon, thus activating electrical inputs towards the dendrites of the next neuron.
The effectiveness of these impulses at the synaptic level is linked to the learning processes and memory of the human being and is or is not strengthened through a process of reweighting.
The human brain contains about one hundred billion neurons and each of them can be connected on average with a thousand other neurons. If we multiply the two numbers, we get a potential of 10^14 synaptic connections.
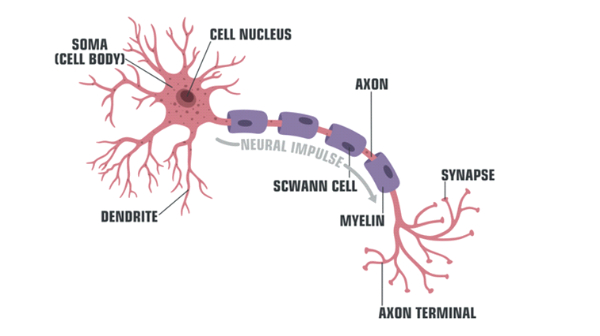
([1]) Recipient portion of the cell body of the neuron. Dendrites are often numerous and branched and extend into the area surrounding the cell body; On their plasma membrane they establish synaptic contacts with the transmitting portions (axons) of presynaptic neurons, and conduct the electrical potential generated by the receptors to the cell body and the emergency cone of the axon of the nerve cell to which they belong.
([2]) Prolongation of the nerve cell, capable of conducting the nerve impulse from the cell body to the periphery and transmitting it to other cells.
Neurons are almost all created at birth, except for very few that can be created in post-natal age, but in fact the neuron is the only human cell that can no longer regenerate after birth. The network that connects them – and above all the formation of new synapses – is very rapid in newborns and continues into adulthood.
Synaptic connections enhanced through the reweighting processes remain active longer – effectively forming long-term memory – while weak, unused connections are removed along with the dendrites to which they are attached.
The first studies of simulating neurons to create Artificial Intelligence were announced in December 1943 by Warren S. McCulloch and Walter Pitts in the publication entitled “A logical calculus of the ideas immanent in nervous activity”.
It is a fundamental combiner with multiple binary numbers input and a single binary output, associated with the idea of being able to create a network of such combiners in order to perform calculations.
However, it is in 1958 that Frank Rosenblatt introduces the first real idea of artificial neuron, called perceptron. The perceptron is a model with weighted input data, which introduces the first real idea of learning, even if in a very elementary form. It represents, in fact, the first model of artificial neural network.
The perceptron is a binary classifier for supervised learning, able to predict whether the input data vector with the appropriately weighted values, belongs to a class or not. The classifier in question uses a linear classification algorithm, like those we have already seen, that is, it receives Xi variables as input and adds them linearly with Wi weights (this part reminds a bit of the dendrites of our neurons)
Y = W1X1 + W2X2 + W3X3 + …
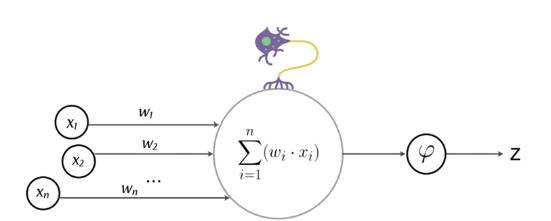
The resulting Y of this linear classifier (the axon of our neuron) is then fed to a nonlinear function called activation function, which we can try to associate with the synapse of the biological neuron.
The activation function is a mathematical function applied to the inputs of the neuron that determines its output. There are various activation functions that depending on the type of neuron are used to optimize learning.
For example, the step function (used in binary classification), the sign function, the sigmoid function (sig) (used in logistic linear regression), the hyperbolic tangent function (tanh) (used in logistic linear regression), ReLu activation function, and the SoftMax function (used for classification on different classes).
Ultimately, we can consider the perceptron as a basic neural network at a single level. If we then connect multiple perceptrons in cascade, at least one input, one intermediate and one output, with each of them that can use classifiers of various kinds (linear and not) we obtain a neural network, with multiple levels.
Normally the intermediate levels between the input and the output are for simplicity referred to as hidden levels.
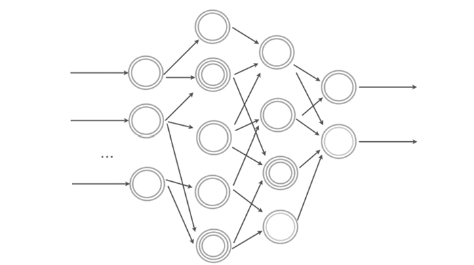
A DNN (Deep Neural Network) multilevel neural network is able to predict complex problems and manage multiple parameters: obviously the computational need increases, besides the fact that debugging and interpretation of the results is inevitably much more complex.
Scikit-learn provides some libraries for models based on Neural Networks; there are also frameworks specialised in Deep Learning and Neural Models developed by different Organisations, such as Tensorflow, MXNet, PyTorch and Keras.
Why has deep learning become important in recent years?
In recent years, a new and decisive impulse to the use of Neural Networks has derived from some important technological innovations introduced in the “data value chain” and which have launched a new era in information processing. Especially:
- Big Data: the availability of large labeled datasets (e.g. ImageNet: millions of images, tens of thousands of classes). The superiority of Deep Learning techniques over other approaches is manifested when large amounts of training data are available.
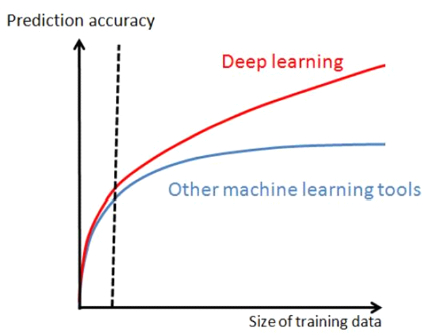
- GPU computing: Training complex models (deep and with many weights and connections) requires high computational power. The availability of GPUs with thousands of cores and GB of internal memory has allowed us to drastically reduce training times: from months to days.
- Vanishing (or exploding) gradient: gradient back-propagation (fundamental for back propagation) is problematic on deep networks if sigmoid is used as an activation function. The problem can be handled with Relu activation (described below) and improved weight initialization (example: Xavier initialization).
Main types of DNN:
There are various types of DNN – Deep Neural Network – that can be classified as follows:
- “Discriminative” feedforward models for classification (or regression) with mainly supervised training:
- CNN – Convolutional Neural Network (or ConvNet)
- FC DNN – Fully Connected DNN (MLP with at least two hidden levels)
- HTM – Hierarchical Temporal Memory
- Feedforward models with unsupervised training (“generative” models trained to reconstruct input, useful for pre-training other models and to produce salient features):
- Stacked (de-noising) Auto-Encoders
- RBM – Restricted Boltzmann Machine
- DBN – Deep Belief Networks
- Recurrent models (RNN) (used for sequences, speech recognition, sentiment analysis, natural language processing, …):
- RNN – Recurrent Neural Network
- LSTM – Long Short-Term Memory
- Reinforcement learning (to learn behaviors):
- Deep Q-Learning
- Generative Neural Networks (GANs)
In the articles that will be published in the coming weeks, we will deal with each type of DNN – Deep Neural Network examining, from time to time, the commitment of Humanativa both in terms of projects carried out and / or in progress, and in terms of research and development of our knowledge.
Article written by Piero Geraci