
In this article, we discuss the innovation of Humanativa’s LLM solutions, where research conducted by our Competence Center and expertise in large LLM projects is transformed into LLM solutions.
Humanativa solutions based on LLM
In general, in previous articles we have given an idea of the “complexity” behind the LLM process (from question to answer) and we have seen that there are many factors that influence the definition of a “fit” solution for a customer based on LLM.
We understand that the techniques to be used may necessarily depend on:
- the type of context of the given project (whether it is domain-specific or not),
- the dynamism or static nature of the specific domain of the data, the current accuracy of large models,
- linguistic aspects (which model responds best in Italian?),
- aspects related to the cost control of proprietary models,
- the need/possibility of offering open source models,
- whether to consider new “compact and lightweight” models, which are also trending upwards during the year,
- and additional specific domains with highly “sensitive” data security regimes that imply non-cloud choices even for LLM queries.
All this complexity, which lies “behind” the use of LLMs, has led us to design a “core” system with a high level of modularity and configurability, making Humanativa’s LLM service solution adaptable, dynamic, and open to specific developments.
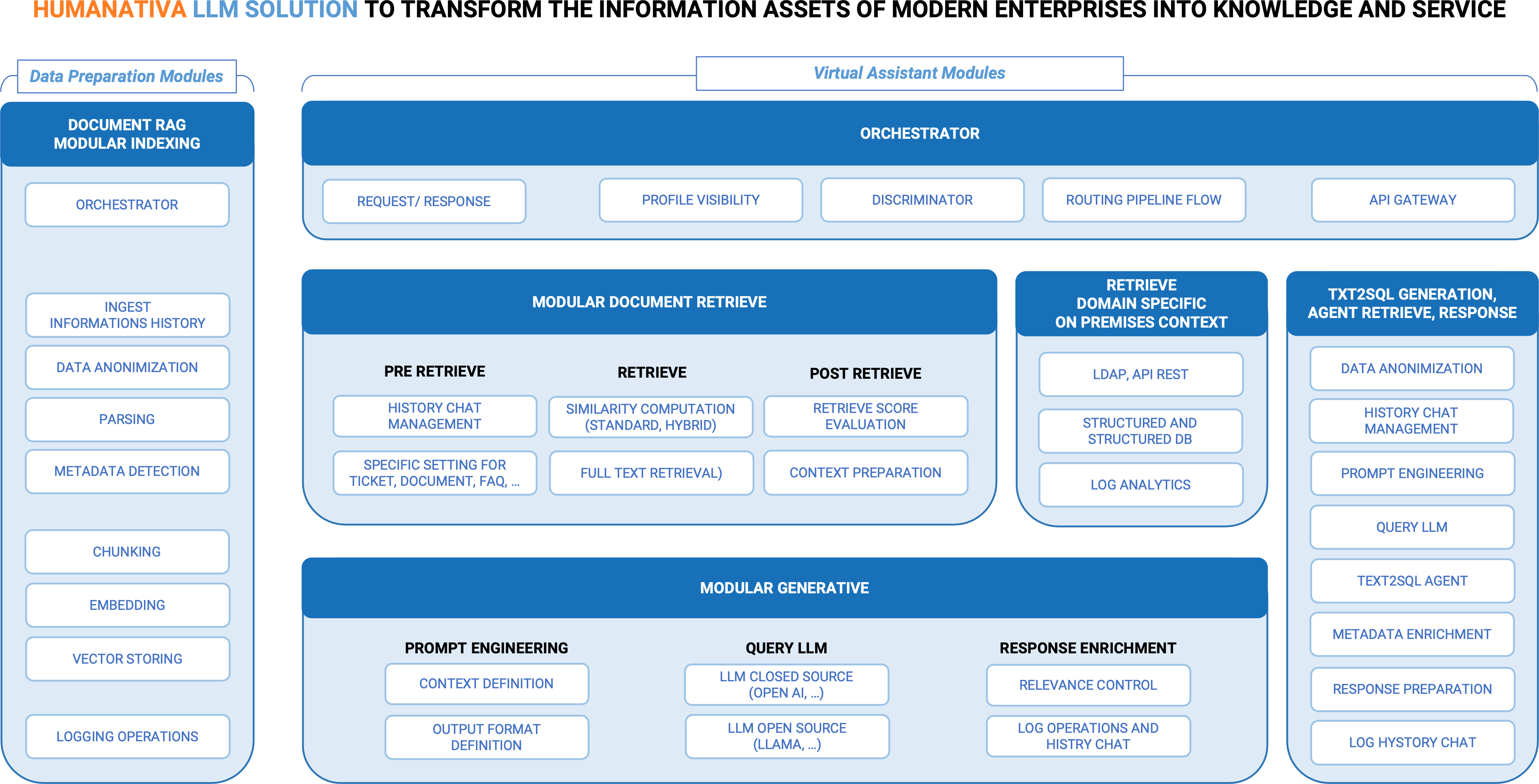
To better explain our approach, as shown in the figure, we have several macro-components, which in turn are composed of specific modules engineered for use in Cloud and/or On-premise system configurations. Let’s take a look at the main components:
- Orchestration and routing of flows: The Humanativa system for LLM was designed to accommodate developments and adapt to cloud or on-premise solutions and/or mixed cloud and on-premise solutions, and was therefore created as a highly configurable system.
To ensure a highly flexible system, we have several components, the most important of which are:
- Macro Modulo Orchestrator, a technological component entirely dedicated to system configurability that guarantees the functional interoperability of even complex LLM workflows. Thanks to Orchestrator, we can deal with situations where it is necessary to:
- coordinate incoming flows;
- route activation pipelines (sequences) between modules;
- coordinate outgoing flows;
- activate new modules to be included in pipelines or deactivate certain modules;
- trigger task automations via API connectors, triggers, or queues;
- define paths based on “profile visibility.”
- Discriminator module to define the routing of a request towards the activation of a specific pre-configured functional path. The module:
- acts as a Super Agent to complete a specific task;
- uses LLM to understand the request in natural language and make a decision to activate a path.
An example: given a user query, it is necessary to understand whether the query relates to “informational-documentary” aspects, “numerical-monitoring” aspects, or “operational control” aspects, activating a RAG path or a Text2SQL path or a specific malfunction check by querying an application log. LLM-related Agent modules are increasingly in demand today because they reduce the need for human intervention in decision-making tasks for specific and repetitive tasks.
- The macro component of Data Preparation for RAG (indexing) consists of basic components for managing the flow that generates knowledge from “domain-specific” documents, with Pre-processing, Chunking, Embedding, and Vector Storing Modules, accompanied by specific Modules for:
- Ingest: for both cloud and on-premise solutions,
- Data Anonymization,
- Metadata processing to increase domain-specific information.
- Macro Component for Retrieving Information from Databases and Logs, i.e., information necessary to provide a response, not necessarily related to the concept of “documents,” but necessary in certain cases to fully define the “context” for the prompt engineering phase. These modules include:
- Secure information retrieval via API Gateway,
- Querying both structured and unstructured databases,
- Application log queries.
- Specific macro component for Test2SQL: from a question in natural language, the question is transformed into an SQL query via LLM, the queries are executed through an agent, and a context is returned to the LLM in order to generate a precise response, either in tabular form or as an attachment.
This feature is considered very useful not only by technicians, but above all by company figures who need to monitor trends in specific areas of company information, asking the system questions whose answers are mainly “numerical” in nature, without necessarily having knowledge of database query techniques (such as SQL).
- Specific algorithms and techniques created by Humanativa to govern and improve certain aspects of the canonical RAG process:
- In the pre-retrieval phase, where we manage the chat history and govern the consistency between questions and answers “in conversational context” and manage configurations according to the type of document class.
- In the Retrieve phase, where we combine various “similarity computation” techniques with other search techniques designed to offer additional ways of finding retrieve results in cases where similarity does not offer adequate or expected results.
- In the post-Retrieve phase, where we use techniques for scoring retrieve results based on different algorithms.
- In the Post-LLM Generation phase, where we have modules for:
- Checking the relevance of the response to the question asked, which is one of the key points for verifying the robustness of an LLM model’s response with respect to the data domain;
- Refining the LLM output using the metadata collected during the system input phase to make the response more contextual and specific.
Which solution approach to recommend to customers
Humanativa’s approach aims to offer a tailor-made LLM solution. This first step, as with any project, is achieved after assessing the starting point (the as-is situation) and the objectives to be achieved. In the case of LLM-based projects in particular, the following aspects are fundamental:
- Technical Approach: we define the best process workflow, which LLM and which RAG technique to adopt, and even which algorithms to use to strengthen certain steps in the RAG process.
- LLM Costs: we identify the costs of adopting open or proprietary LLM models depending on the scope of application.
- Scalability: often linked to the previous point of cost management over time, this is a step that can be decided with the customer, for example by defining the scope of the knowledge base and adding additional data contexts over time.
- Sensitive data: hybrid choices of open and on-premise LLM, cases where all valuable or private information requires protection and security.
- Domain Experts and Users:
- It is essential to interact with the customer’s domain experts who, together with our support, can evaluate the quality of the LLM service.
- It is also essential to know the user profile in order to determine the degree of specialization required in the response of LLM models.
- Solutions with on-premise LLM and LLM in the Cloud. This last aspect is particularly relevant because, as we described at the beginning of the article, there are several open and private LLMs, which means, for example, that in a ‘complex’ solution, we are also able to offer mixed solutions with multiple LLM models in which:
- where necessary, large LLM models are queried via cloud API (such as OpenAI’s GPT available via Microsoft Azure services),
- and where possible, open models can also be used, perhaps even ‘compact’ and ‘lightweight’ ones for specific process tasks through specific LLM agents. This is the case, for example, with the Discriminator Module of the ‘core’ of Humanativa Services for LLM described above, where an Open Model can be used for its specific task of routing the query to the correct pipeline.
To conclude, at Humanativa, as mentioned earlier in this article, we have focused from the outset on designing a modular and configurable solution for LLM services. Conceptually, although our task is not to publish papers, we have also recognized the importance of studies and papers on what is happening with RAG and its evolution towards more modular approaches. Considering the “young age” of RAG and LLM, it is good feedback for us at Humanativa to show that we are in line with current trends, also towards our customers.