
How to improve the ability of LLMs to generate accurate responses in natural language.
Over the past year, as the major proprietary and open-source LLM producers have pushed for market dominance, there have been arguments for and against the “robustness” or ability of LLMs to respond accurately without ending up in so-called “hallucinations.”
This has led both LLM producers and universities to study techniques to improve the ability to generate accurate and precise responses. Among these, the RAG (Retrieval-Augmented Generation) technique is the most established and continuously evolving.
The RAG technique
It is currently considered by “experts” to be almost a mandatory solution in the field of LLM when the knowledge base is very specific and therefore difficult to contextualize by LLMs built to be ‘generalized’ and “multi-purpose.”
At the heart of this technique are three fundamental steps that characterize the so-called “Naive” RAG:
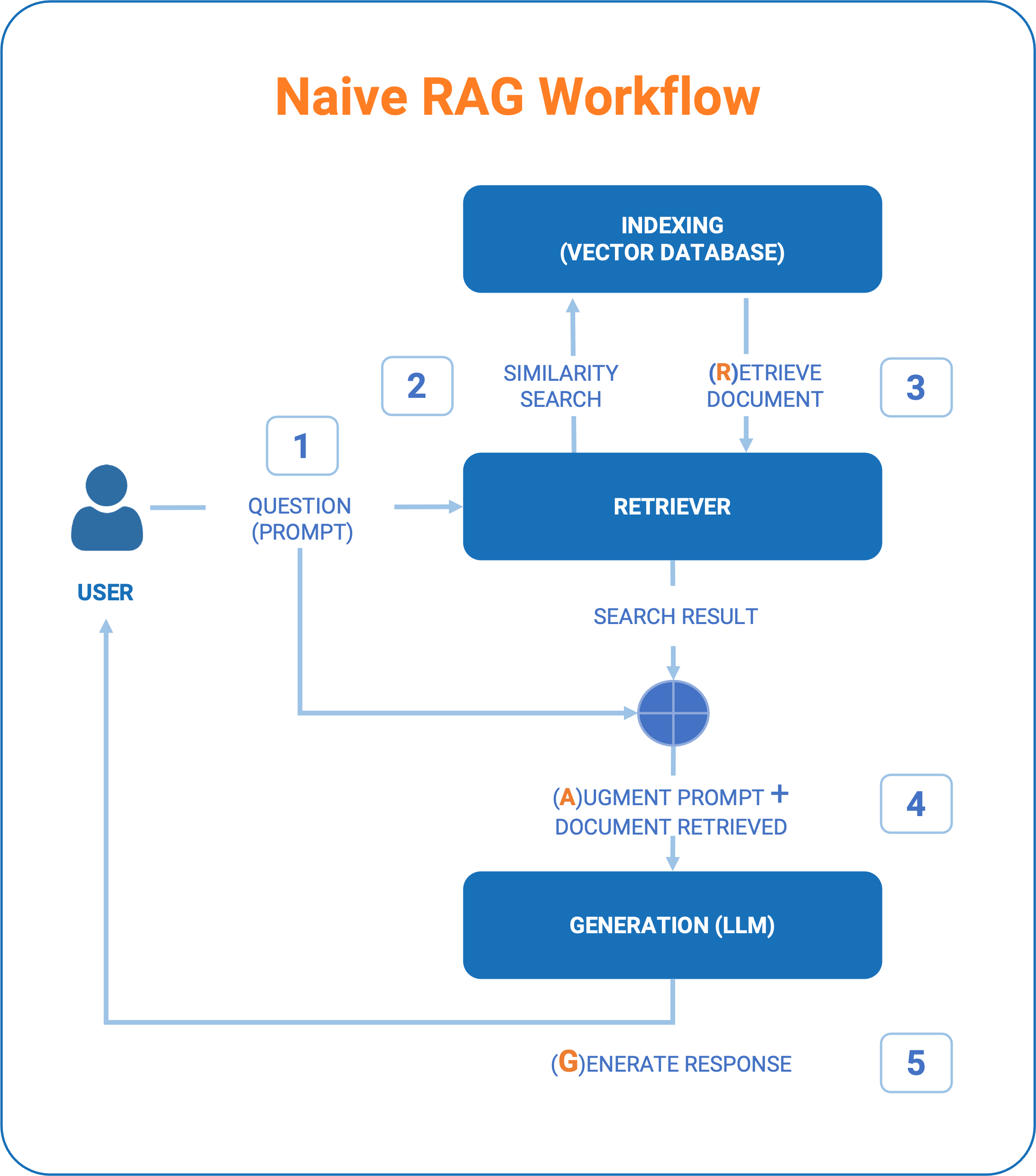
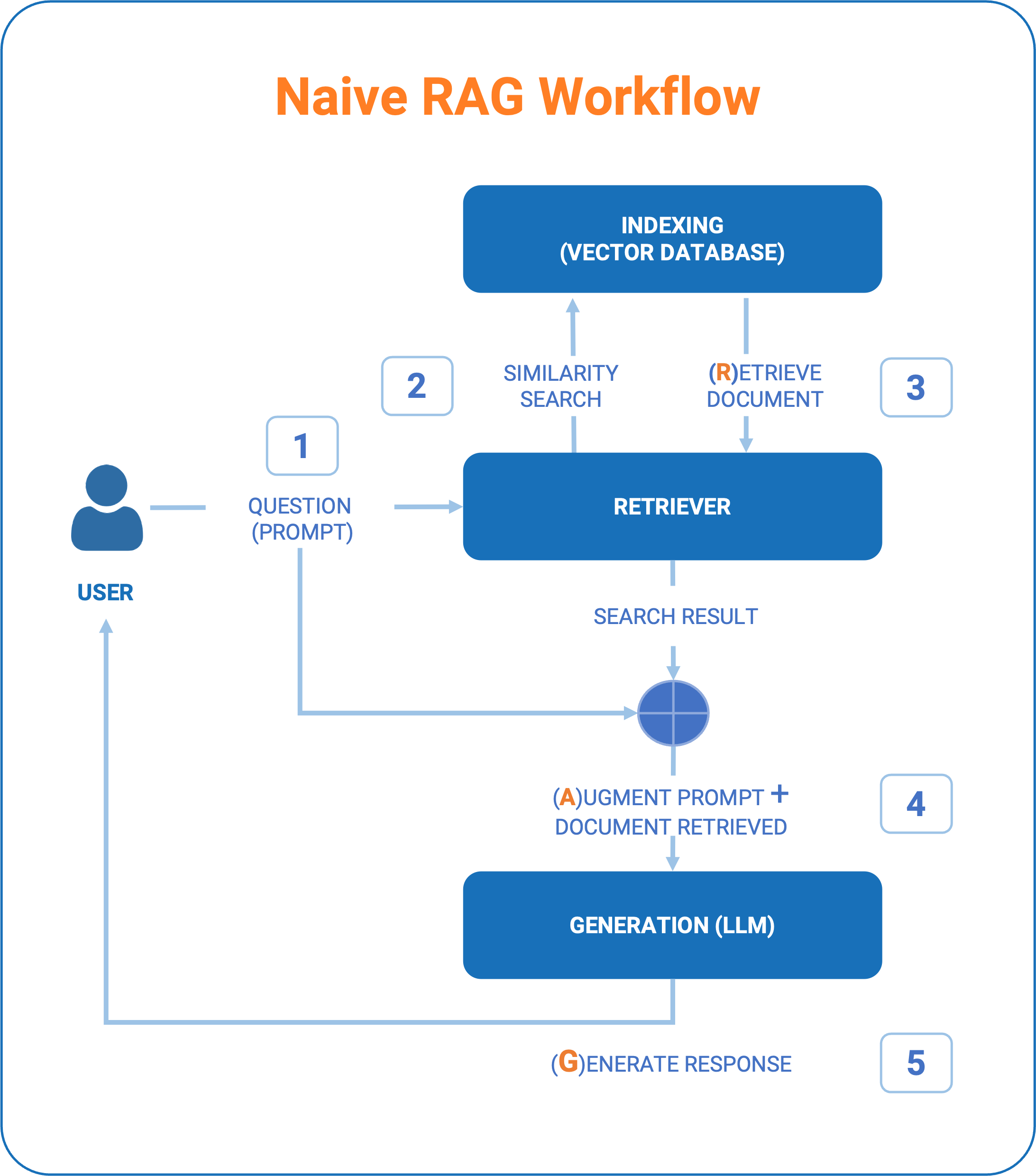
- Indexing: the information (which we will refer to as documents) must be transformed into an “indexed” knowledge base. This initialization phase and then, over time, continuous updating of knowledge is essential for using query methods based on ‘similarity’ criteria in the subsequent “retrieval” phase.
- Retrieve: takes the user’s “question” as input and retrieves the most reliable information using one or more algorithms that allow the identification of the documents that most closely match a correct definition of the “context” to be provided to the LLM response generation.
- Generation: Finally, the generation of the result has two distinctive features:
- a first phase of prompt engineering in which the “true” prompt to the AI model is constructed. We could define it as an “augmented prompt” because it combines the question asked by the user, the basic information retrieved through the retrieve, together with instructions to the model on how to respond and what type of output is expected (formatting, style, etc.). Prompt engineering is therefore a crucial point on which the ability to deliver a good result may depend.
- A second phase of querying the LLM model, which ends with the generation of the response text based on both the model’s knowledge and the retrieved information.
In summary, this technique:
- Allows the computing power of large LLM models to be used, but for a very vertical and specific domain (‘domain-specific’).
- Avoids training costs. In other words, it is a way to avoid training LLM models on a specific data domain, which would be exorbitantly expensive in terms of computational resources, even if an open-source model were available.
- Offers a high expectation of improvement in LLM responses because:
- It allows the LLM model to have an additional domain-specific context to answer questions that require information not contained in the training data of the model used.
- It can potentially provide up-to-date answers on topics contained in the knowledge base that, in a company, for example, change frequently.
- It increases the accuracy of responses from virtual assistants, search engines, and other interactive applications.
RAG: birth, adoption for LLMs, and its recent evolution
The technique was officially born in 2020 by Facebook AI Research (FAIR), and the initial approach was to combine retrieval models with generative models to improve the capabilities of NLP models in tasks that required up-to-date knowledge and detailed information, overcoming the limitations of static language models. (ref. paper “Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks,” published by Patrick Lewis, Ethan Perez, Aleksandra Piktus, and other researchers).
But although the technique was born in 2020, the RAG approach has seen significant adoption since 2023, especially for next-generation LLMs where the focus is on answering complex questions in a contextual way, using information retrieved from domain knowledge.

Therefore, we could say that the RAG technique in the LLM field is still in its infancy and that from 2023 to the present (end of 2025), companies, universities, and papers have been rapidly following one another. We have thus moved from a Naive RAG technique to Advanced RAG and finally to the recent modular approach of Modular RAG. This latest approach, which is constantly evolving, is a collection of additional specialized tasks, increasingly specific, to make the LLM workflow (from question to answer) increasingly robust.
Humanativa’s LLM solution also falls within this third stage of evolution, as it is based on experience gained on large projects in 2024-2025 for various clients, which we will explain in a subsequent article.
RAG and Fine Tuning – Comparing Techniques
Per dfgfdgfd To conclude the discussion on RAG and the possibility of offering an LLM solution that combines domain-specific knowledge and accurate LLM responses, there is one last aspect that is widely discussed in the Data Science community: the comparison between RAG and Fine-Tuning.
Which of these two approaches is the most useful? As always, it depends on the domain data.
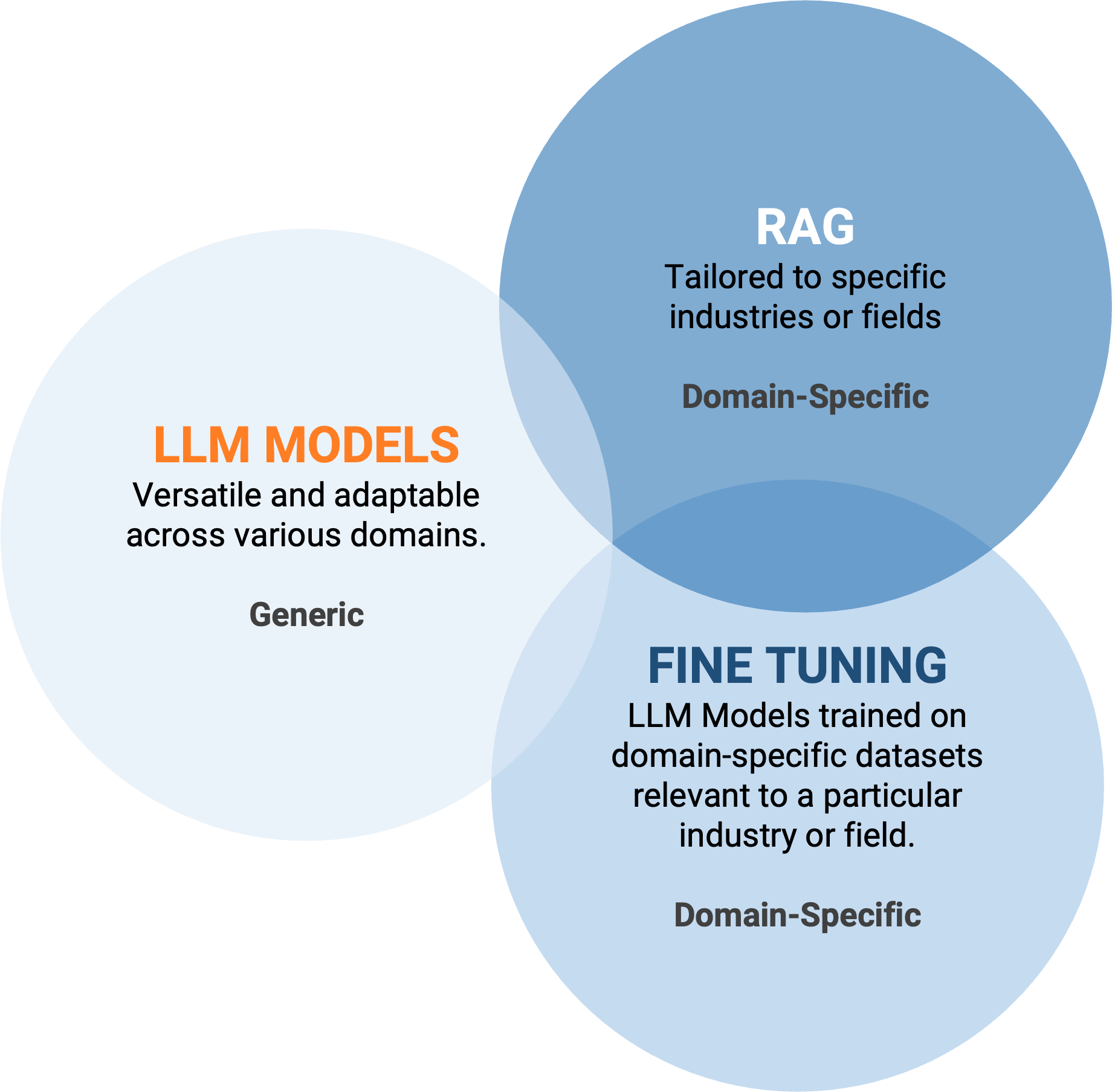
RAG is useful when you can augment the LLM prompt with dynamic data that is not known to an already trained LLM, such as domain-specific data, personal (user) data, real-time data, or context information useful for the prompt.
Fine-tuning, on the other hand, allows the model to learn stable and recurring patterns. However, since it is based on static datasets, the information learned by the model may not be updated over time, making retraining necessary to maintain its relevance.
Obviously, one paragraph is not enough to cover this topic, but it is a fundamental point to consider when approaching the ideal solution for a given domain based on its “dynamism” or the presence of stable and recurring patterns.
In the following articles, we will focus further on Data Preparation for RAG (so-called Indexing), where we will explore, for the pre-processing phase, the use and applicability of the new Visual Language Models (VLM) (artificial intelligence models that combine artificial vision and natural language processing capabilities).