OBIETTIVO
L‘obiettivo del progetto è quello di realizzare un sistema di pre screening intelligente basato su architetture BIG DATA per il controllo dei passeggeri del trasporto aereo con la finalità di aumentare i livelli di sicurezza anti-terrorismo.
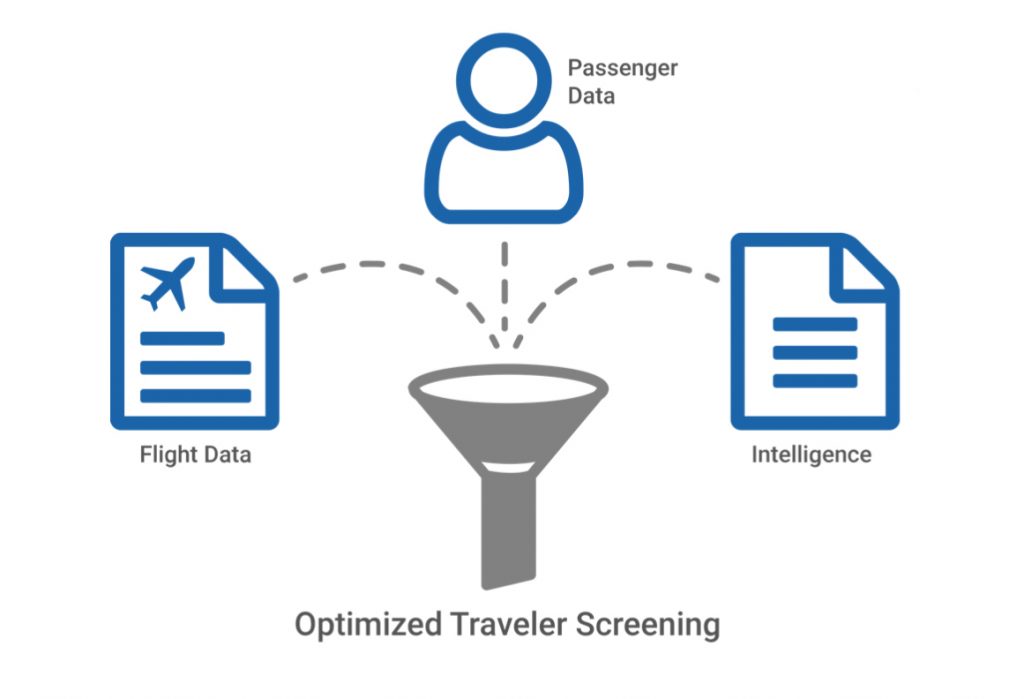
Il sistema si baserà su ciò che è noto come un Passenger Name Record, spesso abbreviato in PNR.
I PNR sono compilati dalle agenzie di viaggi, vettori aerei e tour operators, contengono informazioni quali le condizioni mediche e le disabilità, le preferenze sui pasti, i mezzi di pagamento, ma anche l’indirizzo di lavoro, la email, l’indirizzo IP se si prenota online e le informazioni personali dei contatti di emergenza.
Queste informazioni vengono immagazzinate in una architettura BIG DATA (Hadoop) che è in grado di analizzarle tramite algoritmi di Machine Learning utilizzando modelli comportamentali, opportunamente ingegnerizzati, che analizzano i PNR con l’archivi dati, black-list messe a disposizione dagli enti governativi e gli Open Source Intelligence (OSINT) disponibili sulla rete (siti web, blog, social network, media, motori di ricerca etc..).
Tali elaborazioni rese affidabili ed efficienti grazie all’architettura di calcolo distribuito caratteristica dell’architettura Hadoop, permettono di assegnare un “punteggio di rischio” di terrorismo alla persona in tempo reale.
Tale classificazione dovrà poi essere comunicata alle compagnie aeree per sottoporre la persona sospettata a controllo bagaglio esteso e/o personale, e di contattare le forze dell’ordine, se necessario.
Inoltre permetterà di avere una serie di strumenti di investigazione con elevanti livelli di analisi, poiché verranno realizzati strumenti di data analytics in grado di individuare relazioni tramite l’estrazione di informazioni utili rese disponibili, come luoghi, organizzazioni e persone.
In un flusso di lavoro convenzionale per il controllo dei passeggeri, le agenzie governative hanno poco tempo per reagire ai dati in arrivo dal momento in cui un manifest di passeggero viene generato quando il viaggiatore raggiunge un checkpoint di frontiera.
Questa piattaforma permette di rendere questo processo è più efficiente, poiché puoi iniziare non appena il passeggero acquista il biglietto, ed inoltre permette:
- Importa tutti i dati avanzati sui passeggeri (API).
- Controlla automaticamente tutti i passeggeri.
- Controllare manualmente meno dell’1% dei viaggiatori.
- Cattura terroristi, contrabbando, persone scomparse, visti in eccesso, ecc.
- Promuovere viaggi legittimi.
- Accelera il processo di screening.
- Rende i viaggi globali più sicuri per tutti.
ARCHITETTURA
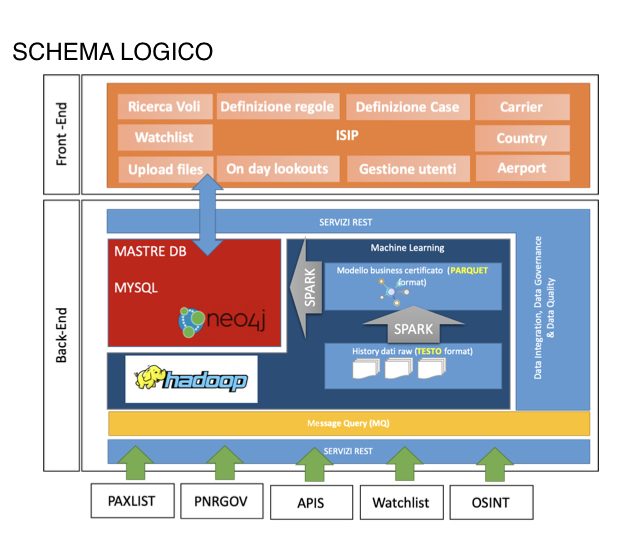
L’architettura della piattaforma logica dovrà prevedere i seguenti layer architetturali:
- Sistema di storage distribuito, basato su hadoop, DB relazionale e Nosql
- Algoritmi di Machine Learning
- Elaborazione Streaming
- Fruizione tramite piattaforma Web – (Angular, java)
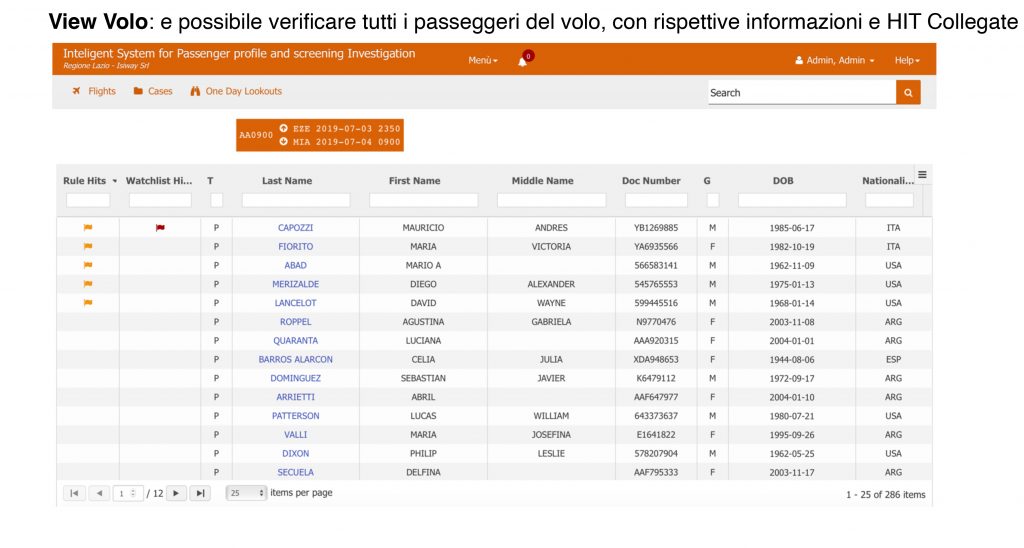
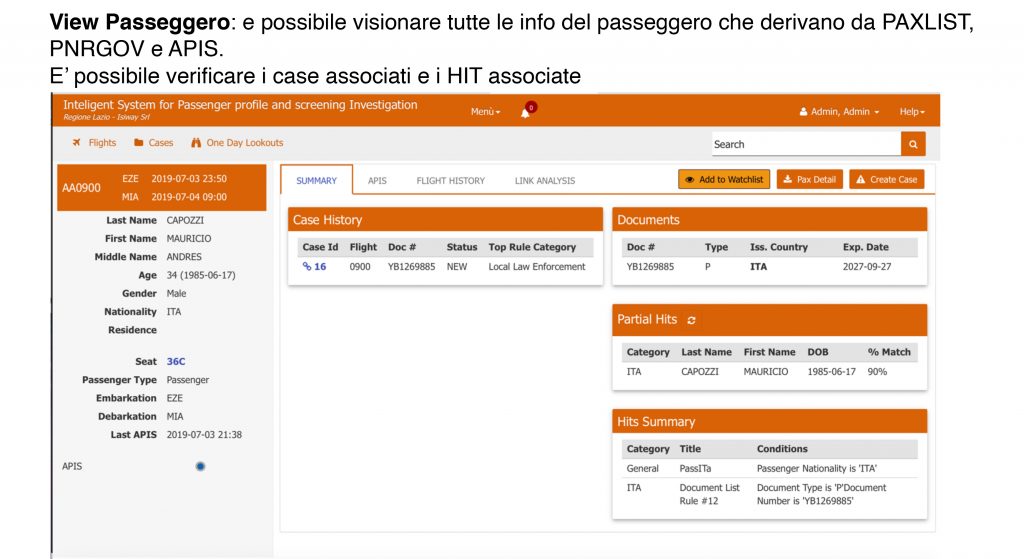
ISIP analizza i dati forniti dai sistemi di controllo delle partenze delle compagnie aeree (API) e dai sistemi di prenotazione (PNR). Rispettivamente, questi messaggi sono conformi ai formati WCO UN / EDIFACT PAXLST e PNRGOV.
- UN / EDIFACT PAXLST 02B e versioni successive
- PNRGOV 11.1 e versioni successive
PIATTAFORMA ISPI
l’Intelligent system for passenger profile and screening investigation.
(ISIP) è un’applicazione web per migliorare la sicurezza delle frontiere.
Consente alle agenzie governative di automatizzare l’identificazione dei viaggiatori aerei ad alto rischio prima del viaggio previsto.
Le Nazioni Unite hanno invitato i membri a utilizzare i dati Advance Passenger Information (API) e Passenger Name Record (PNR) per prevenire il movimento di viaggiatori ad alto rischio.
L’Organizzazione mondiale delle dogane (WCO) ha stretto una partnership con la protezione doganale e delle frontiere degli Stati Uniti (US-CBP) a causa della convinzione condivisa che ogni agenzia di sicurezza delle frontiere dovrebbe avere accesso agli strumenti più recenti. US-CBP ha reso questo repository disponibile al WCO per facilitare lo spiegamento per i suoi stati membri.
PIATTAFORMA DI BACK-END
La piattaforma di Back-end è formata dai seguenti elementi:
1) Infrastruttura Hadoop (cloudera) per algoritmi di machine learning:
a) Detection di Pattern non Usuali da PAXLIST, PNRGOV e APIS
Identificazione di Outlier tramite Reti Neurali e LOF
2) Persistenza dei dati per gestione piattaforma di front-end
a) basata su Maria DB
b) Hadoop (cloudera) per addestramento ed esecuzione machine learning
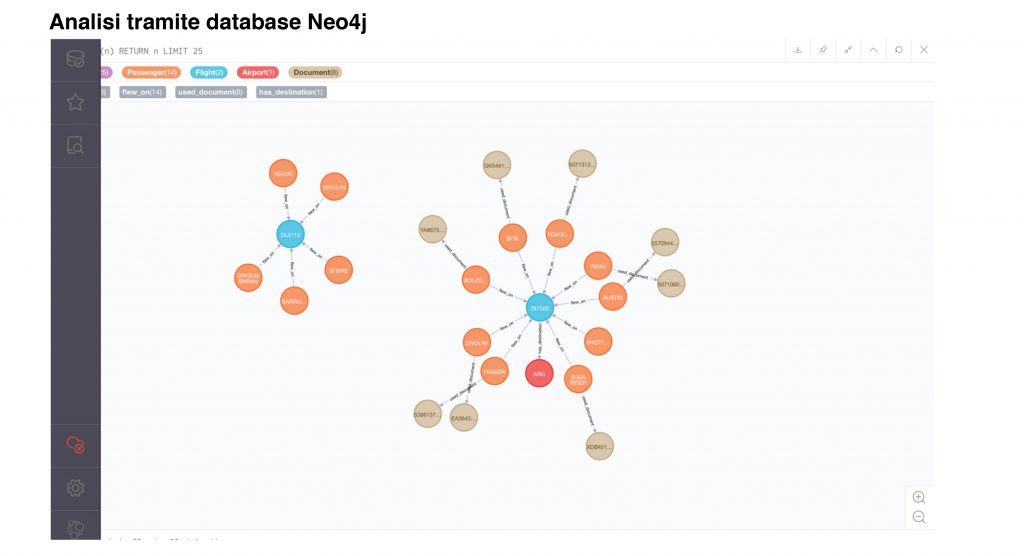
c) Neo4j per analisi ed identificazione Hit tramite regole a Grafo
3) Interfacce di elaborazione
a) Servizi di parser PAXLIST, PNRGOV e APIS
b) Servizi di MQ per analisi e caricamento dati in real-time
c) Procedure Etl (pentaho) per caricamento dati in Hadoop e Neo4j
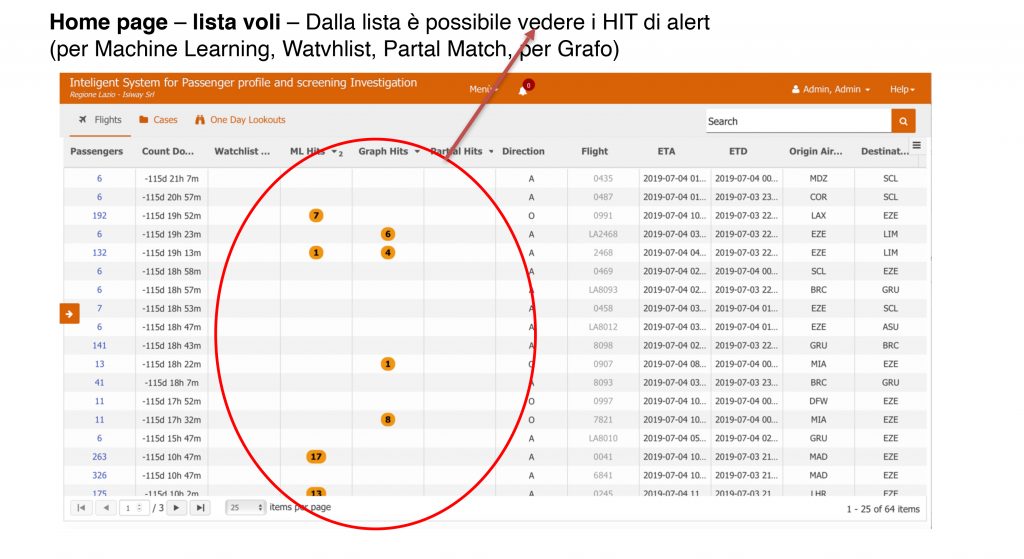
d) Servizi di elaborazione HIT (per Machine learning, per Grafo, per Match Jaro-Winkler, per regole e per Watchlist
4) Tecnologia: Java 8, Apache Tomcat 8, MariaDB 10.0 Stable, Apache ActiveMQ e Angular
PROCESSO DI ELABORAZIONE DI BACK-END
I processi di back-end:
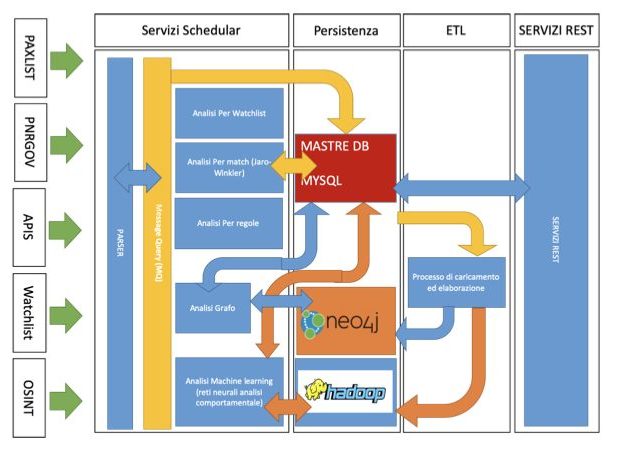
1) Servizio di Parser
Questo processo di Background è in ascolto in una cartella del server, dove ha il compito di processare i file PAXLIST, PNRGOV e APIS ed alimentare una coda MQ
2) Servizio schedular di elaborazione: dalla coda MQ ci sono i seguenti processi in trend
a) Processo di persistenza verso il DB
b) Processo di HIT per Watchlist
c) Processo di HIT per Match Jaro-Winkler
d) Processo di HIT per Regole
e) Processo di HIT per Grafo
f) Processo di HIT per Machine learning (reti neurali) – Identificazione di Outlier tramite Reti Neurali e LOF
3) Processi ETL (pentaho)
a) Caricamento verso Neo4j dei dati
b) Caricamento verso Hadoop dei dati
4) Servizi REST a supporto del Front-End
PIATTAFORMA DI BACK-END