
Nel precedente articolo abbiamo descritto in linea generale il funzionamento delle reti neurali, in questa seconda pubblicazione analizzeremo invece nel dettaglio le “Convolutional Neural Network” (CNN), una tipologia di reti neurali di tipo feed-forward.
Le reti neurali convoluzionali, nascono dagli studi condotti sulle cortecce prefrontali animali e sono impiegate, sin dal 1980, nei processi di image recognition.
Nelle CCN vengono applicati dei filtri che vanno a riconoscere particolari correlazioni o pattern all’interno dell’immagine stessa, al fine di generare delle feature ottimali da fornire poi in input ad una rete neurale (di norma fully-connected).
Dal punto di vista matematico, l’operazione di convoluzione consiste nel “moltiplicare” tra di loro due matrici opportunamente traslate per calcolare la risultante, di cui una rappresenta l’immagine oggetto di analisi e l’altra il filtro che viene applicato.
Con le operazioni di convoluzione è possibile, infatti, applicare filtri specifici per estrarre un set di informazioni, ad esempio nel riconoscimento immagine si potrebbero estrarre i bordi di sinistra con il primo filtro, quelli di destra con il secondo, gli spigoli con il terzo etc. … fino a raggiungere il livello di accuratezza ottimale.
Nel processo di convoluzione abbiamo tre elementi fondamentali:
- L’immagine di input: una matrice di pixel rappresentativa dell’immagine. Ad esempio, sia 32×32 per visualizzare un numero, una lettera o un’icona.
- La feature detector o Kernel: una matrice che agisce da filtro attraverso l’operazione di convoluzione. Ad esempio 3×3 o 7×7.
- La feature map: la matrice risultante dalla convoluzione tra immagine di input e il Kernel.
Al termine di questo processo si ottiene la feature map, una matrice più piccola rispetto a quella relativa all’immagine di input.
Ad esempio, filtrando un’immagine 32×32 con un kernel 7×7, otterremo una matrice risultante di dimensione 26×26.
Nel processo di convoluzione si perdono alcune informazioni sull’immagine ossia quelle non contenute nella feature detector o kernel prescelta; tuttavia, quelle informazioni saranno contenute in altre future map.
Infatti, utilizzando più filtri di convoluzione si otterranno molteplici feature map, ciascuna delle quali memorizzerà feature distintive della nostra immagine, ad esempio il contorno destro, gli spigoli, i colori più scuri etc.
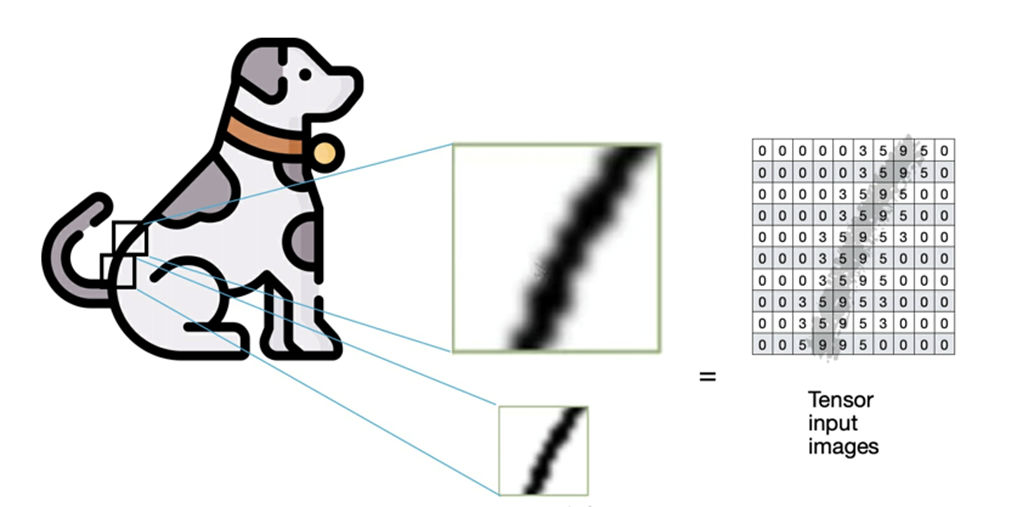
In figura l’immagine del cane viene codificata ottenendo la matrice di input.
In realtà all’algoritmo CNN verranno passate in input una serie di immagini di training, quindi un vettore di matrici chiamato in gergo anche Tensor (tensore).
Come detto, se alla matrice di input rappresentativa dell’immagine, vengono applicati diversi filtri con più operazioni di convoluzione si otterranno una serie di feature map.
Le feature map ottenute vengono ad essere a loro volta “sotto-campionate” attraverso un processo che prende il nome di pooling.
Pooling è la tecnica che consente di ridurre la complessità considerando solo una parte dei dati.
Si tratta di un processo di dimensional reduction che consente di semplificare la complessità di una CNN.
Due sono le tecniche pooling: max pooling e average pooling. In pratica si effettuano operazioni di calcolo del massimo o del valor medio su un subset di caselle della matrice in input. L’obiettivo del pooling è minimizzare la complessità, quindi ridurre l’overfitting.
Il processo di convoluzione e quello di sotto campionamento tramite pooling, sono entrambi ripetuti, applicando tra l’altro funzioni di attivazione non lineari alle varie feature map, ovvero la Rectified Linear Unit (RELU).
Dopo N processi di convoluzione – Pooling – RELU, occorrerà trasformare le pooled feature map in un vettore a una dimensione, utilizzando il processo chiamato Flattening (appiattimento).
Sarà così possibile fornire in input il vettore risultante ad una rete neurale fully connected, dove ogni nodo risulterà connesso con tutti gli altri: questo è in pratica l’hidden level della nostra CNN che si occupa della predizione e classificazione dell’immagine.
Al termine del processo si giungerà il livello di output, dove verranno applicate due tipologie di funzioni di attivazione per completare la classificazione dell’immagine: la funzione sigmoidea in caso di classificazione binaria, oppure la sua variante multi-dimensionale chiamata softmax, adatta in caso di classificazione relativa a molteplici categorie.
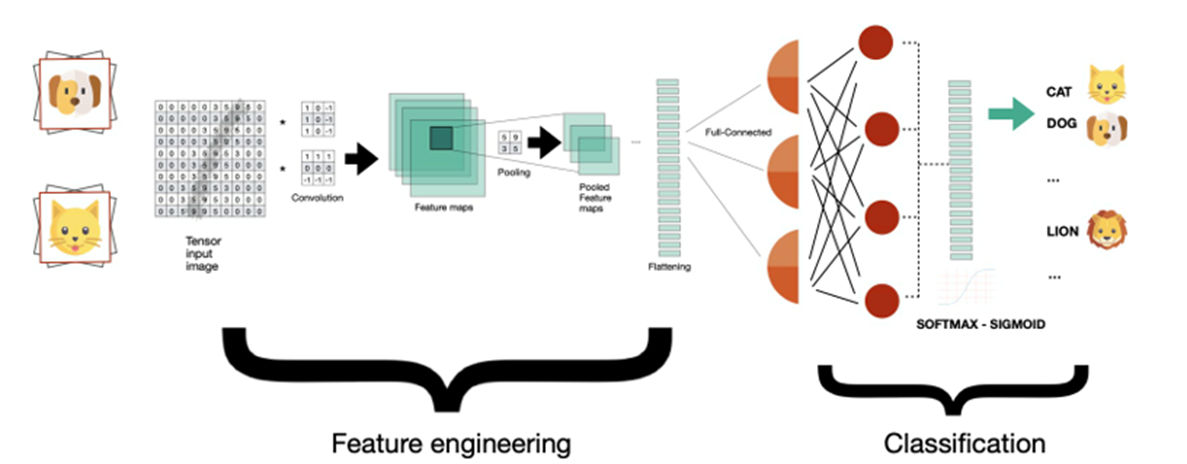
Analizzando la figura precedente, la rete CNN è suddivisa in due processi:
- il primo racchiude i livelli iniziali dove vengono preparate le feature utilizzando i processi di convoluzione, pooling e flattening. L’obiettivo è quello di estrarre le caratteristiche dell’immagine che siano presentabili al processo successivo, la rete neurale di classificazione.
- Il secondo processo è costituito da una rete neurale tradizionale, nel nostro caso completamente connessa per classificare al meglio l’immagine in base alle feature ricevute in input.
Cliccando sul link sottostante è possibile visualizzare un esempio di CNN con rete convoluzionale in 2D: https://www.cs.cmu.edu/~aharley/vis/conv/flat.html
Progetti Humanativa
Uno dei progetti di Humanativa in ambito CNN, ancora in corso, è incentrato sulla possibilità di estrarre da un file video (film/documentari) informazioni relative a volti, oggetti e località.
Il risultato di questo progetto sarà poi utilizzato per implementare i servizi di research image per estrarre ulteriori informazioni dai motori di ricerca.