
Introduzione
In questo articolo riportiamo un estratto dalla sperimentazione condotta nel 2022 sui dati dei flussi dei passeggeri presso i Point Of Interest (POI) di una location di trasporti sul territorio nazionale. In particolare:
- saranno esposti i risultati dei modelli di Forecast relativi ad un Punto di Accesso, ottenuti attraverso un framework di Machine Learning ideato, progettato e sviluppato in Isiway.
- confronteremo i risultati con una baseline basata sui flussi reali e il modello in uso presso la location di trasporti prescelta per la sperimentazione;
- illustreremo una simulazione di un servizio di MLOps al fine di dimostrare l’efficacia di una strategia di monitoraggio accompagnata da una procedura di learning on-line basata su un trigger di alert sulle performance del modello in produzione.
In questo caso un modello di Forecast non è semplicemente un modello che realizza una adeguata performance rispetto ad una metrica di letteratura adottata come riferimento per la valutazione dei risultati, ma deve essere un modello che risolve un problema di business ben definito: la ottimizzazione della gestione del personale presso un POI in funzione dei flussi dei passeggeri.
Materiali e metodi
Sono stati utilizzati i dati messi a disposizione relativi al punto di accesso prescelto, in cui sono riportati, per il periodo che va dal 2019 al 2021 e ad intervalli di cinque minuti, il reale flusso dei passeggeri presso il punto di accesso e la stima fornita dal modello di forecast interno.
I modelli di forecast qui presentati sono sviluppati attraverso il Forecast Engine, un framework di Machine Learning nel linguaggio Python, ideato, progettato e sviluppato in Isiway per la automazione del processo di importazione, esplorazione dei dati e generazione di modelli. Le funzionalità del motore sono in linea con i processi di AutoML resi disponibili dai cloud provider.
Il framework opera sulla base delle diverse librerie presenti in letteratura, da quelle di statistica classica a quelle più recenti basate sul paradigma del deep learning e delle reti neurali ricorrenti ed è in continua espansione sulla base dei recenti sviluppi proposti dalla comunità scientifica.
Nella figura seguente ne sono riportate le funzionalità.
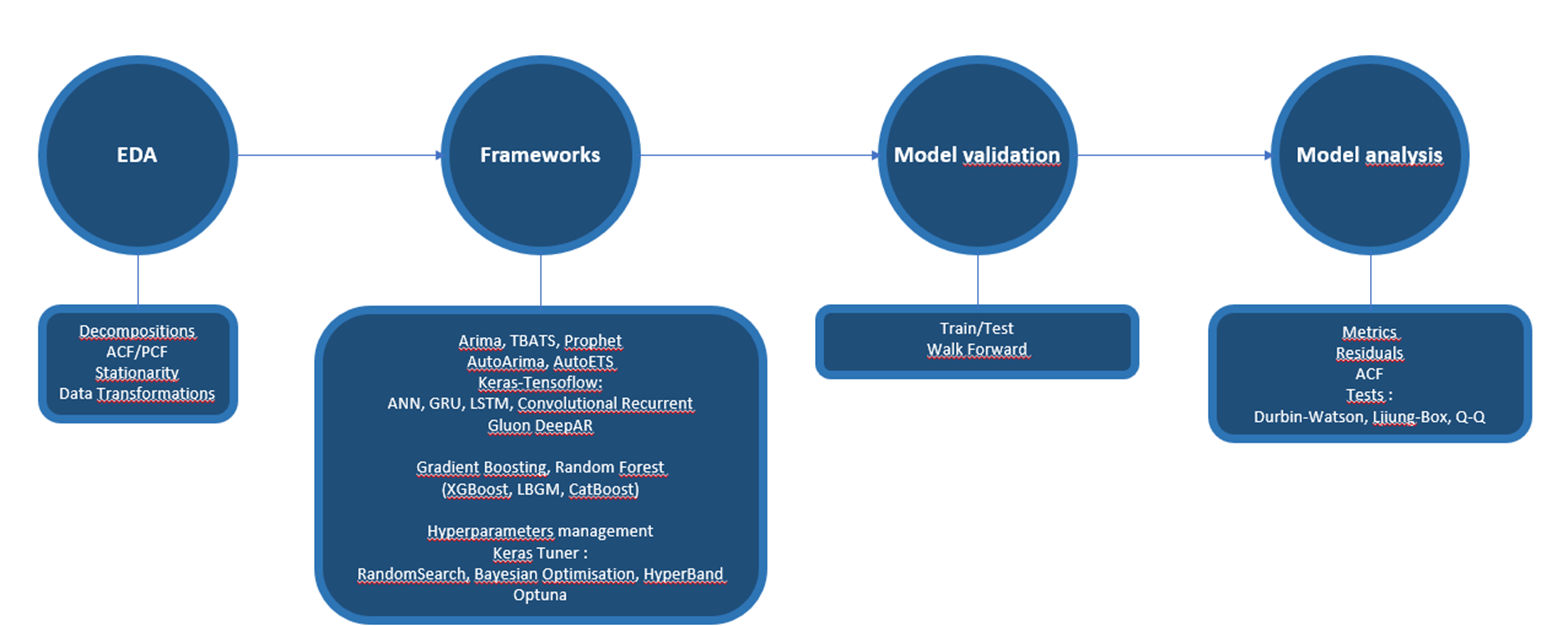
Figura 1. Il framework Forecast Engine
Il modulo EDA ha le seguenti funzionalità:
- Decomposizioni delle Time Series (classica e STL)
- AutoCorrelation Function e Partial Correlation Function, per le analisi dei lag si autocorrelazione utilizzati nei modelli statistici classici di tipo ARIMA
- Test di stazionarietà
- Trasformazioni del dato sulla base dei test (es. BoxCox)
I modelli di forecast disponibili sono:
- Arima, AutoArima
- TBATS
- ETS, AutoETS
- Prophet
- Da TensorFlow: ANN, GRU, LSTM, CNN
- Da GluonTS: GluonDeepAR
- Gradient Boosting e Random Forest (dalle librerie XGBoost, LilghtGBM e CatBoost)
Le procedure di Iperparametrizzazione sono basate su:
- Keras Tuner (Ramdom Search, Bayesian Optimisation e HyperBand)
- Optuna
I modelli sviluppati sono analizzati attraverso:
- le metriche (es. RMSE, R2)
- l’analisi dei residui, con i test Durbin-Watson, Ljiung-Box e Q-Q
- la AutoCorrelation Function.
Il protocollo di sviluppo dei modelli è riportato nella figura seguente.
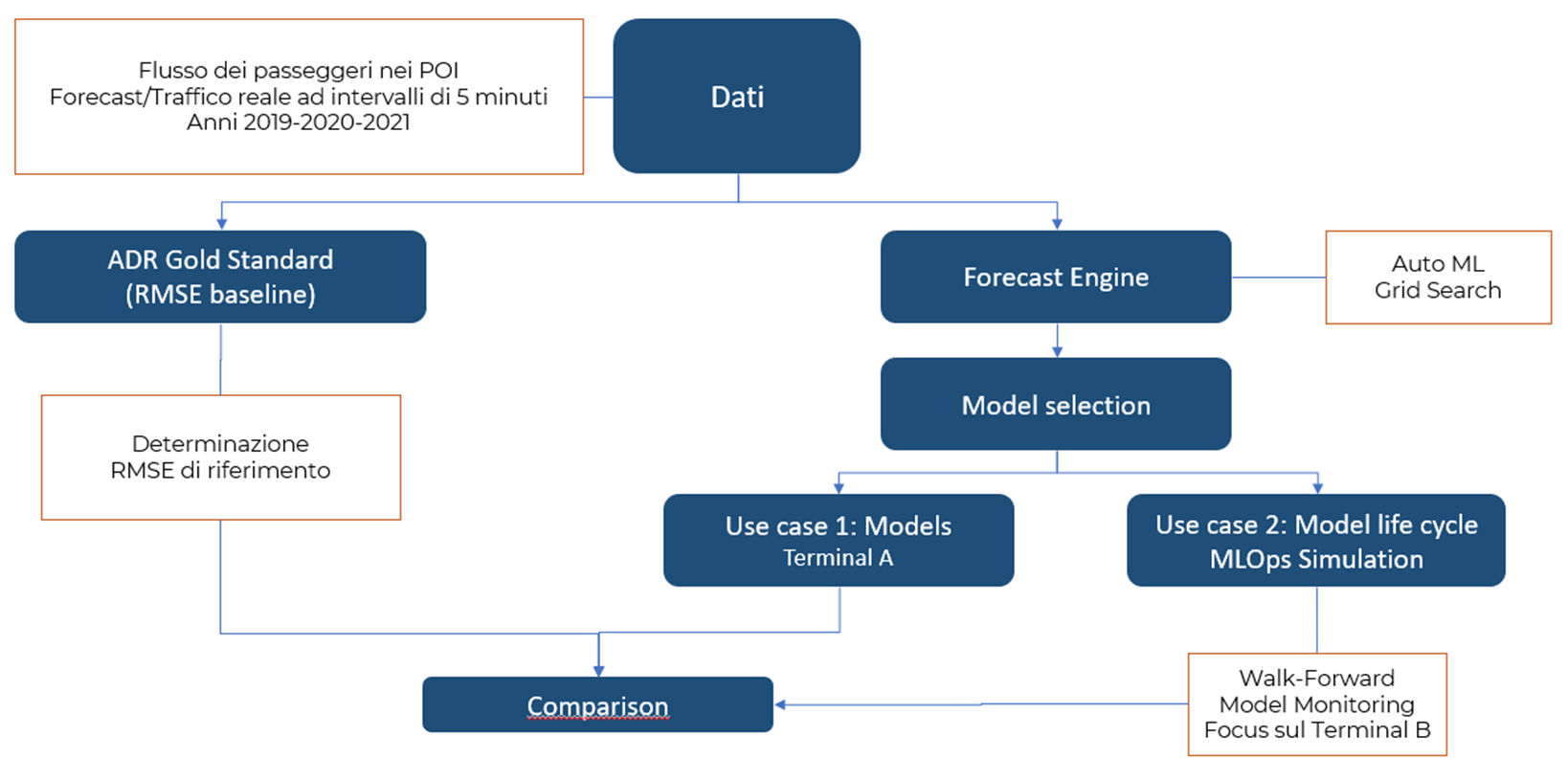
Figura 2. Protocollo di analisi
La prima fase del protocollo è la definizione di un Gold Standard, una metrica che possa costituire una baseline per la valutazione adeguata del modello prodotto dal Forecast Engine. Nella figura seguente riportiamo le metriche disponibili per un problema di forecast e, in particolare la metrica adottata, l’RMSE.

Figura 3. Metriche per il Forecast
La Root Mean Square Error (RMSE) ha i seguenti vantaggi:
- è espressa nelle stesse unità dei dati.
- è facilmente calcolabile.
- consente il confronto tra diversi modelli in base al criterio che gli errori abbiano una distribuzione normale.
Come anticipato, riporteremo i risultati di quello che nella figura 2 è indicato come Use Case 2, poiché in questo caso abbiamo simulato un processo di Machine Learning Operations (oggi comunemente sotto il nome di MLOps), articolato nelle fasi di Monitoring e Continuous Delivery che consente di automatizzare il controllo del modello in produzione e la eventuale necessità di svilupparne uno nuovo nel caso di degrado delle performance, in genere dovuta al data drift. Questo tipo di gestione di un modello è ormai messo a disposizione da tutti i cloud provider.
In pratica abbiamo adottato il protocollo di validazione del modello di tipo Rolling Origin Walk-Forward nella fase di produzione, valutando il modello ad ogni ingresso di nuovi dati e definendo un trigger di alert di degrado delle performance basato su un threshold fissato sull’RMSE.
La validazione di un modello di forecast attraverso il protocollo Walk-Forward è il gold standard per lo studio delle Time Series e corrisponde al metodo k-fold cross validation nell’ambito dello sviluppo dei modelli supervisionati. Ad ogni step, il modello prodotto da un campione di training di dimensioni fissate è validato su un campione costituito da dati successivi a quelli di training e di dimensioni fissate. Entrambi I campioni “scorrono” nel tempo secondo un intervallo prefissato. Ad ogni step è verificata la bontà del modello e la metrica finale che definisce la performance globale del modello è semplicemente una media.
Se l’origine del campione di training è fissata, ad ogni step del processo il campione si espanderà, come illustrato nella figura seguente.
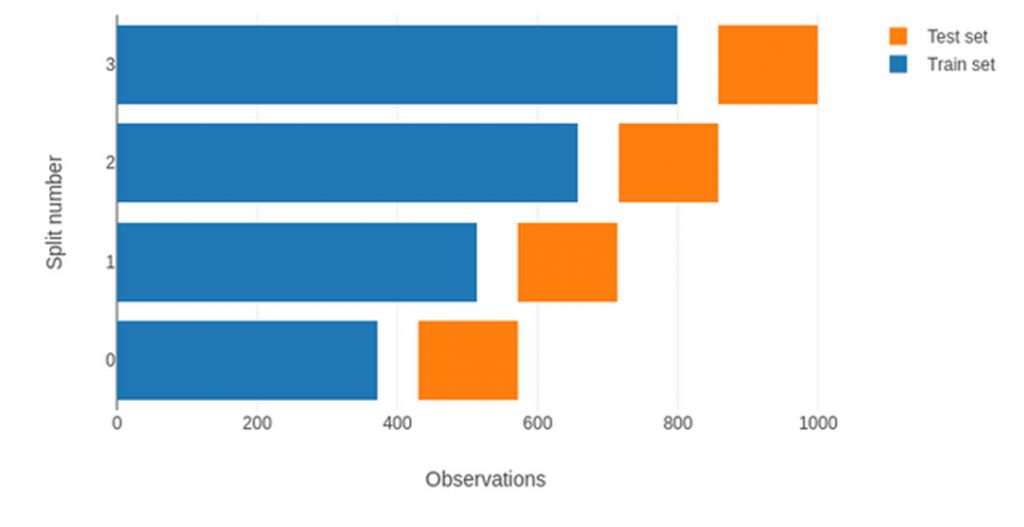
Figura 4. Protocollo di validazione Walk-Forward con expanding window
Se all’inizio del processo l’origine del campione di training è impostata come mobile (rolling origin), il campione di training avrà dimensioni fisse e il proprio intervallo temporale sarà ridefinito ad ogni step.
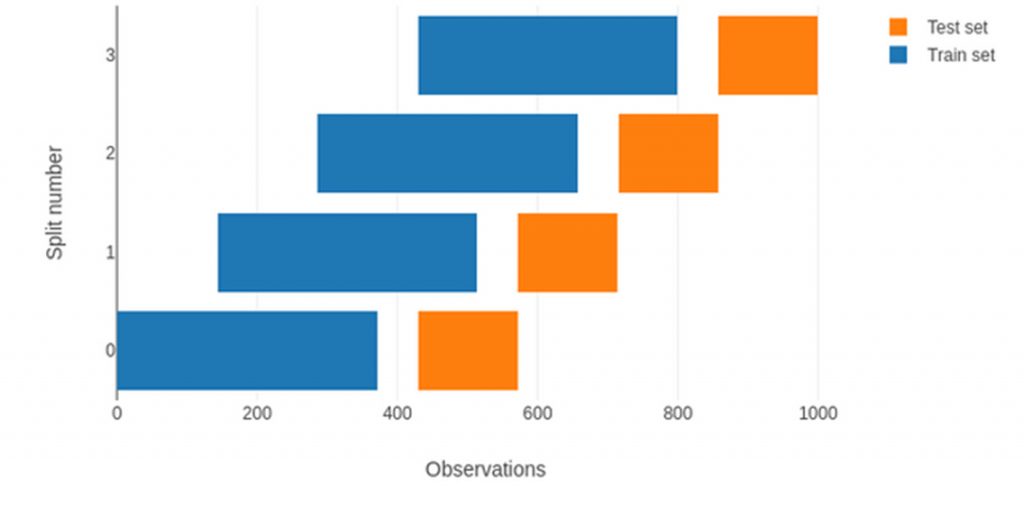
Figura 4. Protocollo di validazione Walk-Forward con rolling origin
Sperimentazione
L’analisi che qui viene riportata è articolata in tre fasi:
- sviluppo di un modello sui dati del 2019 (“modello 2019”);
- inferenza del modello sui dati del 2020 e 2021 al fine di verificarne la robustezza;
- implementazione della simulazione MLOps.
Sviluppo del modello
La finestra temporale che definisce il numero delle features in input, derivante dalla riformulazione del problema in chiave supervisionata, è data da un numero di lag pari a 288 (numero di rilevazioni in un giorno con campionamento di 5 minuti).
Attraverso il Forecast Engine abbiamo definito una batteria di test basata sugli algoritmi riportati nella tabella 1.
| N, | Model |
| 1 | Keras Sequential |
| 2 | Keras Sequential (Deep Learning) |
| 3 | Sequential with Tuner (Tuner Hyper-Parameters Optimisation) |
| 4 | Gated Recurrent Unit 1 (GRU) |
| 5 | Gated Recurrent Unit 2 (GRU) |
| 6 | Long Short Term Memory 1 (LSTM) |
| 7 | Convolutional Recurrent (CNN-GRU, Experimental) |
| 8 | Gradient Boosting XGBoost 1 |
| 9 | Gradient Boosting XGBoost 2 |
| 10 | Gradient Boosting XGBoost_RandomForest |
| 11 | Gradient Boosting CatBoost (Optuna Hyper-Parameters Optimisation) |
Naturalmente, il processo di definizione dei modelli può essere notevolmente esteso. In questa sede vogliamo porre l’accento non solo sui risultati ottenuti, ma anche sulla metodologia di sviluppo dei modelli.
Il modello che ha ottenuto le performance migliori è una rete neurale Sequential (Keras) con due strati di tipo hidden, la cui architettura è riportata nella figura seguente.
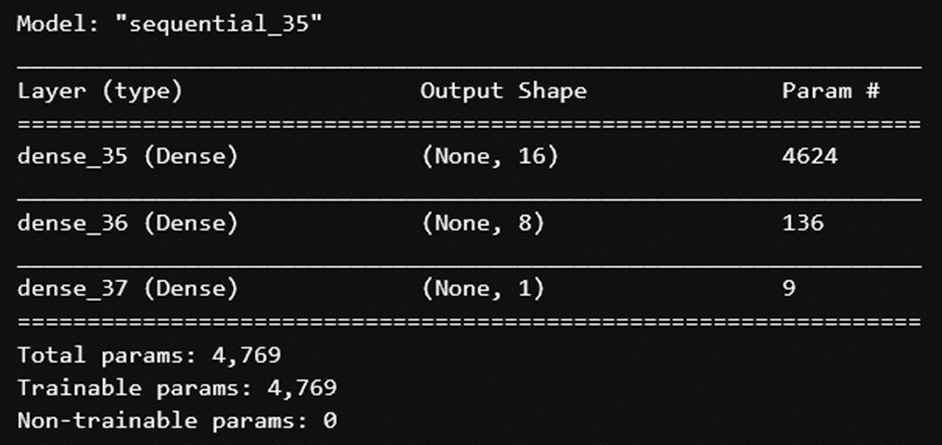
Figura 5. Architetture del modello Sequential che ha ottenuto i migliori risultati
I risultati sono riportati nella tabella seguente, in cui sono riportati anche i risultati sul campione di training, al fine di verificare la presenza di overfitting o underfitting.
| RMSE | MAE | MSE | R2 | R2Adj | |
| Train | 17.272 | 10.442 | 298.33 | 0.924 | 0.924 |
| Validation | 8.615 | 5.503 | 74.214 | 0.854 | 0.853 |
Il modulo di valutazione dei risultati forniti dal Forecast Engine fornisce le seguenti tre analisi:
- Analisi Residui. Questi devono essere non correlati (la presenza di correlazioni indica la presenza di informazioni che il modello non ha intercettato) e devono essere i.i.d., avere una distribuzione normale con media nulla e una varianza costante.
- Test Durbin-Watson, per cui un valore prossimo a 2.0 indica che ci sono evidenze di autocorrelazione.
- ACF (funzione di autocorrelazione). I valori devono essere prossimi allo zero: il 95% degli spikes dovrebbe essere compreso nell’intervallo ±2/√T dove T è la lunghezza della serie temporale
Nella figura 6 è riportata l’analisi dei residui. Il test Durbin-Watson ha indicato un valore di 1.81, per cui i residui non evidenziano tracce significative di autocorrelazione.
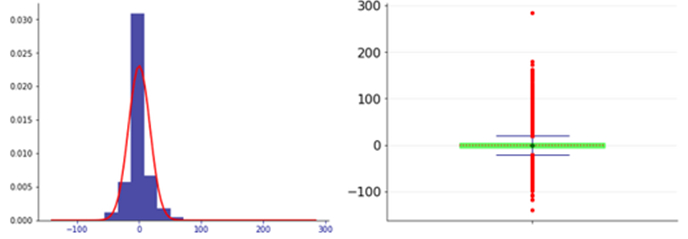
Figura 6. Distribuzione dei residui
Nella figura 7 è riportato il grafico della AutoCorrelation Function, che evidenzia la bontà complessiva del modello.
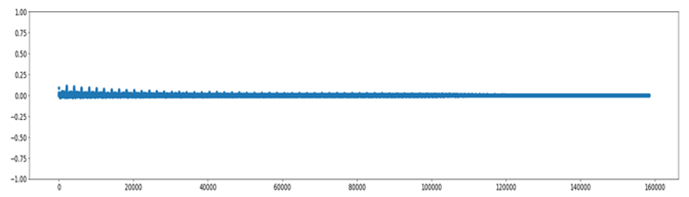
Figura 7 ACF.
Inferenza del modello sui dati del 2020 e 2021
Anno 2020
Il valore dell’RMSE è 7,32 e il test Durbin-Watson indica il valore 1,73.
Nelle figure seguenti sono riportati, rispettivamente, l’analisi dei residui e la ACF
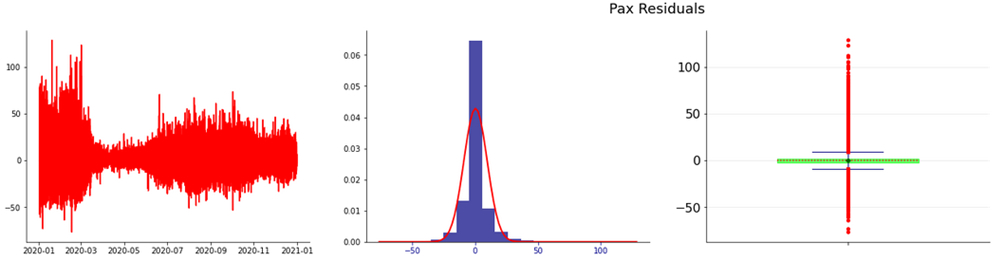
Figura 7. Residui e distribuzione dei residui
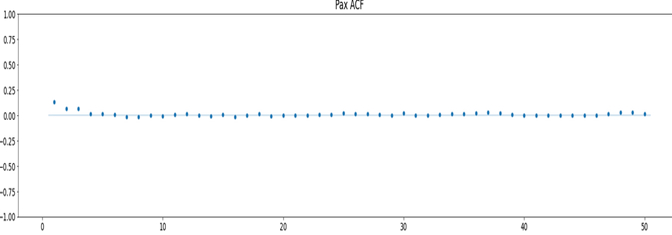
Figura 8 ACF
Anno 2021
Il valore dell’RMSE è 8.50 e il test Durbin-Watson indica il valore 1,81.
Nelle figure seguenti sono riportati, rispettivamente, l’analisi dei residui e la ACF
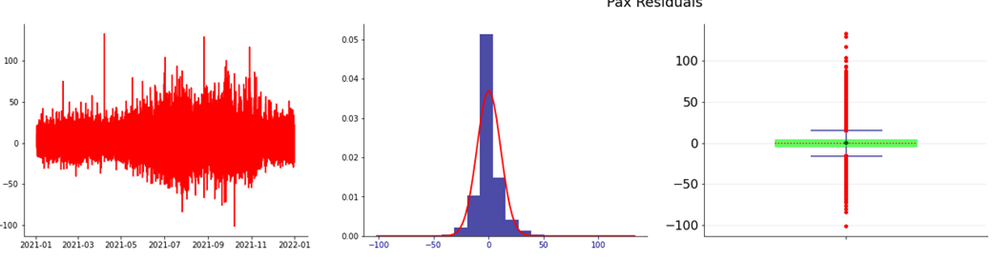
Figura 9. Residui e distribuzione dei residui
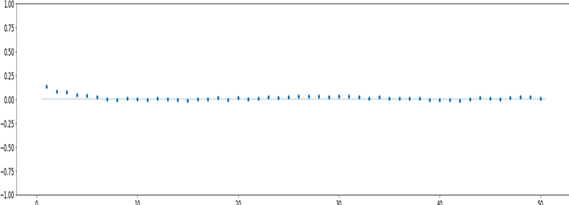
Figura 10 ACF
Nella tabella seguente sono riportati i risultati complessivi, che evidenziano una buona tenuta del modello basato sui dati del 2019.
| Modello | RMSE | Durbin-Watson |
| 2019 | 8.61 | 1.81 |
| 2020 | 7.32 | 1.73 |
| 2021 | 8.50 | 1.81 |
Simulazione MLOps
Il protocollo simulato è basato sulle seguenti fasi:
- “Modello 2019” in produzione;
- Determinazione di un threshold relativo al valore dell’RMSE al di sopra del quale il modello non è ritenuto performante;
- Inferenza sui dati delle 24 ore successive;
- Rolling origin: la finestra temporale del campione di training è spostata di 24 ore utilizzando lo stream del dato reale;
- Monitoring del “modello 2019” senza aggiornamenti;
- Monitoring del modello con trigger di aggiornamento:
- Se l’RMSE del modello sui dati correnti è inferiore al threshold, il modello viene confermato;
- Se l’RMSE del modello sui dati correnti è superiore al threshold, è azionato un trigger di degrado delle performance: in questo caso è necessario avviare una fase di learning al fine dello sviluppo di un nuovo modello la cui performance sia inferiore al threshold di riferimento. L’aggiornamento del modello è una necessità nel caso in cui si evidenzi un data drift, dovuto ad eventi esterni (come pandemie o crisi economiche). Questa opzione permette di risolvere tempestivamente il problema. Naturalmente è una procedura più onerosa, ma consente di mantenere un livello adeguato di performance dei modelli.
- Se la procedura di aggiornamento on-line del modello non produce il modello desiderato, si rende necessario un nuovo ciclo di produzione dei modelli attraverso il Forecast Engine (off-line) con una analisi del dato che evidenzi le ragioni del degrado del modello in produzione.
Monitoring del “modello 2019” senza aggiornamenti
In questo caso si vuole verificare la tenuta del “modello 2019” sui dati degli anni 2020 e 2021 con una procedura di validazione Walk-Forward e un threshold di riferimento impostato a 10.0, senza eseguire una nuova fase di learning.
Nella figura seguente è riportato l’andamento della simulazione
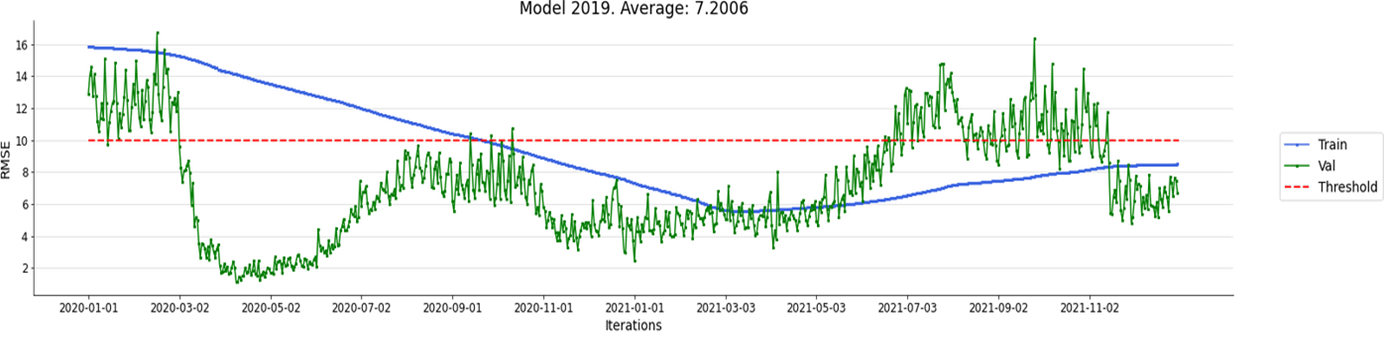
Figura 10 Validazione del Modello 2019 senza aggiornamenti
Le performance sono buone: l’RMSE medio è di 7,2. Il threshold di riferimento 10,0 adottato è decisamente rigoroso, ma la scelta è stata dettata per verificare il miglioramento dovuto al protocollo di Walk-Forward. Il valore soglia è stato superato fino al 13 Aprile 2020 sul campione di training e in 167 occasioni sul campione di validazione nel 2021.
Monitoring del “modello 2019” con aggiornamenti on-line.
Nella figura 11 è riportato l’andamento della simulazione con trigger di aggiornamento, al fine di verificare l’ipotesi di miglioramento delle performance rispetto al “modello 2019” lungo tutto l’intervallo di analisi dal 2020 al 2021. Il threshold di riferimento (RMSE) fissato è 10,0.
Come è lecito attendersi, il miglioramento rispetto al «modello 2019» è netto, per entrambe i campioni. L’RMSE è sempre sotto il threshold di riferimento e la media complessiva è 4,68 contro 7,2 del «modello 2019».
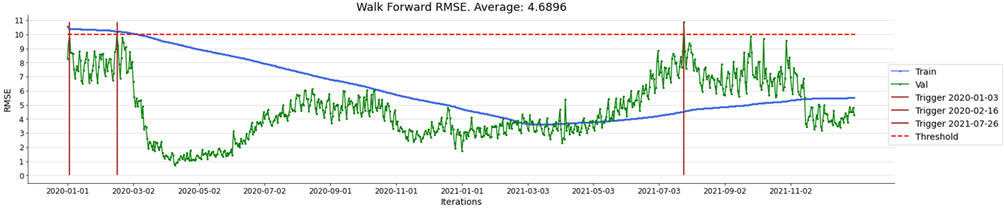
Figura 11 Validazione del Modello 2019 con aggiornamenti
I trigger di degrado delle performance sono scattati solo in tre occasioni, come riportato nella tabella seguente.
| Data Trigger | RMSE pre-aggiornamento | RMSE post-sggiornamento |
| 2020-01-03 | 10.043 | 8.707 |
| 2020-02-16 | 10.16 | 9.22 |
| 2021-07-26 | 10.8 | 8.82 |
È interessante notare la dinamica dell’RMSE dei relativi trigger nel periodo in cui la pandemia Covid-19 ha determinato una riduzione del traffico in base alle politiche di lockdown. La strategia di continuous learning in produzione qui proposta si rivela efficace nel “reagire” alle dinamiche variabili che hanno contraddistinto l’anno 2020 e la fase “post pandemica” del 2021.
Confronto con la baseline originaria
Nella tabella seguente riportiamo le baseline della metrica RMSE calcolata sui dati a disposizione, per ogni anno e per tutto il periodo 2019-2021.
| Periodo | RMSE |
| 2019 | 27.11 |
| 2020 | 16.08 |
| 2021 | 19.5 |
| 2019-2021 | 21.74 |
In figura è riportato il confronto su base mensile tra:
- i risultati del protocollo con il “modello 2019” fissato e non aggiornabile;
- i risultati del protocollo con il “modello 2019” con Walk-Forward on-line basato su trigger di aggiornamento;
- le metriche baseline.
La funzione di aggregazione dell’RMSE è, naturalmente, la media.

Figura 11 Confronto baseline vs modelli Forecast Engine
L’efficacia del “modello 2019” e, in particolare, del modello 2019 con protocollo MLOps è evidente. Nella tabella successiva riportiamo un confronto su tutto il periodo 2020-2021.
| Campione | Modello 2019 | MlOps | Baseline | |
| Test | Media | 7.19 | 4.68 | 15.84 |
| StdDev | 3.21 | 1.95 | 7.53 | |
| Train | Media | 9.44 | 6.18 | |
| StdDev | 3.08 | 2.15 |
Conclusioni
I risultati sono decisamente promettenti, ma potrebbero essere ulteriormente migliorati attraverso il Forecast Engine con protocolli di grid search più completi rispetto a quelli sviluppati e mostrati in questo articolo, utilizzando in maggiore misura le funzionalità di iper-parametrizzazione rese disponibili da Keras Tuner e Optuna.
Attraverso il Forecast Engine si possono perseguire ulteriori obiettivi:
- replica dei risultati sugli altri POI;
- verifica della possibilità di ottenere adeguate performance a partire da una riduzione dei dati di training;
- verifica delle performance passando da una formulazione nei termini di un problema supervisionato di regressione a un problema di classificazione supervisionata multinomiale. In questo caso gli output (i flussi di passeggeri) andranno discretizzati. La strategia di discretizzazione dovrà dipendere necessariamente da una funzione di costo definita: la divisione in bins dovrà generare classi omogenee ognuna delle quali deve essere caratterizzata da una identica gestione delle risorse nell’ambito di un problema di ottimizzazione.
Il framework Forecast Engine di Isiway è un prototipo sviluppato anche nell’ottica di una implementazione sui cloud provider poiché:
- il motore può essere replicato a livello di script o reso disponibile come container;
- è in linea con il paradigma AutoML
Il protocollo è basato su paradigma ML OPS in ambiente cloud: il monitoraggio continuo del modello consente di verificare la robustezza del modello nel corso del tempo e, soprattutto, automatizzare le procedure di update del modello basata su trigger di alert definiti a partire da threshold di riferimento.