
In questo articolo, affrontiamo l’innovazione delle soluzioni LLM firmate Humanativa dove la ricerca condotte dal nostro Competence Center e la competenza in grandi progetti LLM viene trasformata in soluzioni LLM.
Soluzioni Humanativa basate su LLM
In generale, negli articoli precedenti abbiamo dato una idea della “complessità” che c’è dietro il processo LLM (da domanda a risposta) ed abbiamo visto che sono molti i fattori che incidono nel definire una soluzione “fit” per un Cliente basata su LLM.
Abbiamo compreso che le tecniche da utilizzare necessariamente possono dipendere:
- dal tipo di contesto del dato progetto (se è domain-specific o meno),
- dalla dinamicità o staticità del dominio specifico dei dati, dalla accuratezza attuale dei Modelli di grandi dimensioni,
- dagli aspetti linguistici (quale modello risponde meglio in italiano?),
- dagli aspetti legati al controllo dei costi dei Modelli proprietari,
- alla necessità/possibilità di offrire modelli open source,
- se considerare i nuovi modelli “compatti e leggeri” anche questi in tendenza ad aumentare nel corso dell’anno,
- e ulteriori domini specifici con regimi di sicurezza del dato del contesto altamente “sensibile” che implica scelte non-cloud anche per l’interrogazione LLM.
Tutta questa complessità, che ruota “dietro” all’utilizzo degli LLM, ci ha portato a progettare un sistema “core” con un alto livello di modularità e configurabilità, che rende la soluzione per servizi LLM di Humanativa adattabile, dinamica e aperta a evoluzioni specifiche.
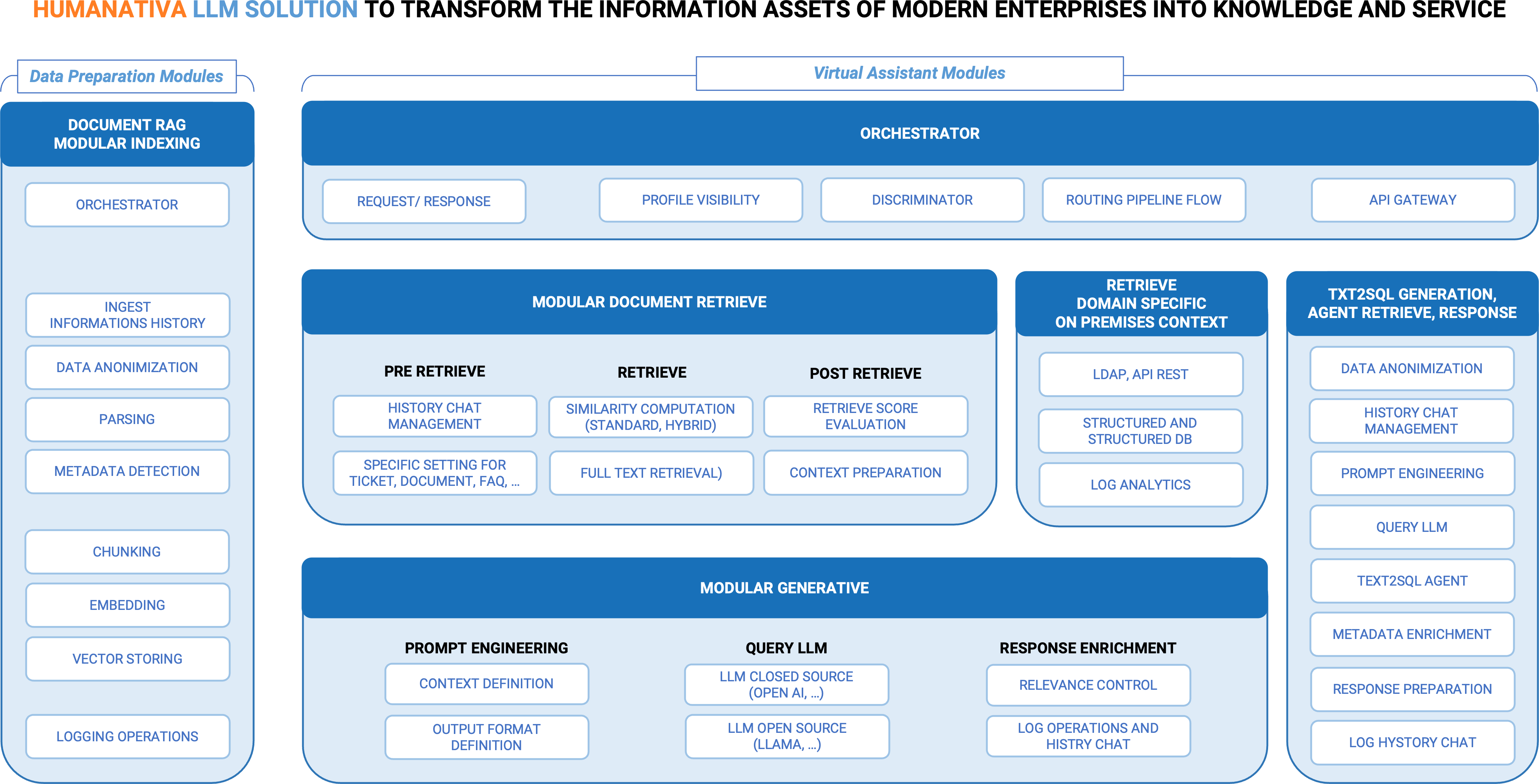
Per meglio spiegare il nostro approccio, come indicato nella figura, disponiamo di diversi macro-componenti, composti a loro volta da specifici moduli ingegnerizzati per poter essere usati in configurazioni di sistema Cloud e/o On-premise. Illustriamo i componenti principali:
- Orchestrazione e instradamenti dei Flussi: Il sistema Humanativa per LLM nasce per ospitare evoluzioni e per potersi adattare a soluzioni cloud o on-premise e/o soluzioni miste cloud e on-premise, e nasce quindi come un sistema altamente configurabile.
Per avere un sistema altamente flessibile, disponiamo di diversi componenti, in cui i più importanti sono:
- Macro Modulo Orchestrator, un componente tecnologico completamente dedicato alla configurabilità del sistema e che garantisce la interoperabilità funzionale dei workflow LLM anche complessi. Grazie all’Orchestrator, possiamo far fronte a situazioni in cui sia necessario:
- coordinare i flussi in ingresso;
- instradare pipeline (sequenze) di attivazione tra i moduli. ;
- coordinare il flusso in uscita;
- attivare nuovi moduli da inserire in pipeline o disattivare determinati moduli;
- innescare automazioni di task via api connector, trigger o code;
- definire percorsi in funzione della “profile visibility”.
- Modulo Discriminator per definire l’instradamento di una domanda verso l’attivazione di uno specifico percorso funzionale pre-configurato. Il modulo:
- agisce come un Super Agent per completare un compito preciso;
- utilizza l’LLM per comprendere la domanda in linguaggio naturale e prendere una decisione per attivare un percorso.
Un esempio: data una domanda dell’utente occorre capire se la domanda è rivolta ad aspetti “informativo-documentali” o ad aspetti “numerici – di monitoraggio” o ad aspetti di “controllo operativo”, attivando un percorso RAG od un percorso Text2SQL o uno specifico controllo di malfunzionamento interrogando un log applicativo. Moduli di Agent legati all’LLM sono sempre più richiesti oggi perché riducono la necessità di intervento umano a fronte di task di decisione per compiti specifici e ripetitivi.
- Macro componente di Data Preparation per il RAG (indexing), è costituito da componenti di base per gestire il flusso che genera la conoscenza da “documenti” di tipo “domain-specific”, con Moduli di Pre-processing, Chunking, Embedding e Vector Storing, accompagnati da Moduli specifici di:
- Ingest: sia per soluzioni in cloud che on premise,
- Data Anonimization,
- Trattamento dei metadati per aumentare le informazioni di tipo “domain-specific”.
- Macro Componente per il Reperimento di informazioni da Database e Log, ovvero sia informazioni necessarie per offrire una risposta, non necessariamente legati al concetto di “documenti”, ma necessari in certi casi a definire compiutamente il “contesto” per la fase di prompt engineering. Tra questi moduli:
- Reperimento di informazioni via Api Gateway in sicurezza,
- Interrogazione di banche dati sia strutturate che non strutturate,
- Interrogazioni di log applicativi.
- Macro Componente specifico per il Test2SQL: da una domanda in linguaggio naturale, si trasforma la domanda in una query SQL via LLM, si eseguono le query attraverso un agent, si restituisce un contesto all’LLM per poter generare una risposta puntuale o tabellare o in forma di allegato.
Funzione considerata molto utile non soltanto da tecnici, ma soprattutto da figure aziendali che hanno necessità di monitorare andamenti di determinati ambiti informativi aziendali, ponendo domande al sistema la cui risposta è prevalentemente di tipo “numerico”, senza avere necessariamente conoscenza di tecniche di interrogazione di una base dati (come l’SQL).
- Algoritmi e Tecniche specifiche create da Humanativa per governare e migliorare alcuni punti del processo RAG canonico:
- In fase di pre-Retrieve dove gestiamo la history chat e governiamo la coerenza tra domande e risposte “in contesto conversazionale” e gestiamo configurazioni a seconda della tipologia di classe di documento.
- In fase di Retrieve, dove affianchiamo alle varie tecniche di “similarity computation” altre tecniche di ricerca studiate per offrire ulteriori vie di reperimento dei risultati di una retrieve nei casi in cui la similarity non offra risultati adeguati o attesi.
- In fase post-Retrieve, dove utilizziamo tecniche scoring dei risultati della retrieve basate su diversi algoritmi
- In fase diPost-LLM Generation, dove disponiamo di moduli per:
- Controllo della aderenza della risposta rispetto alla domanda posta, che è uno dei punti chiave per verificare la robustezza della risposta di un modello LLM rispetto al dominio dei dati;
- Raffinamenti dell’output dell’LLM utilizzando anche i metadati raccolti in fase di input al sistema, per rendere la risposta più contestuale e circoscritta.
Quale approccio di soluzione consigliare ai Clienti
L’approccio di Humanativa ha come fine offrire una soluzione LLM su misura. Questo primo passo, come per qualunque progetto, si raggiunge dopo un rilevamento del punto di partenza (la situazione as-is) e degli obiettivi da raggiungere. Nel caso di progetti basati su LLM in particolare sono fondamentali questi aspetti:
- Approccio Tecnico: definiamo il miglior workflow di processo, quale LLM, quale tecnica RAG adottare, fino anche a quali algoritmi utilizzare per fortificare determinati passi del processo RAG.
- I Costi dell’LLM: identifichiamo i costi nell’adozione di Modelli LLM open o proprietari a seconda dell’ambito di applicazione.
- Scalabilità: spesso legata al punto precedente di gestione dei costi nel tempo, è un passo che può essere deciso con il cliente, ad esempio perimetrando le knowledge base ed aggiungendo ulteriori contesti di dati nel tempo.
- Dato “sensibile” scelte ibride di LLM open e on premise, i casi in cui tutte le informazioni preziose o private richiedano protezione e sicurezza.
- Esperti di Dominio e Utilizzatori:
- È fondamentale interagire con esperti di dominio del Cliente in grado di valutare insieme al nostro supporto la bontà del servizio LLM
- È altresì fondamentale conoscere il profilo degli utilizzatori per determinare il grado di specializzazione necessaria nella risposta dei modelli LLM.
- Soluzioni con LLM on premise e LLM in Cloud. Questo ultimo aspetto è rilevante soprattutto perché, come abbiamo descritto ad inizio articolo, esistono diversi LLM sia open che privati, e questo significa ad esempio che in una soluzione “complessa” siamo in grado anche di offrire soluzioni miste con più modelli LLM in cui:
- dove è necessario si interrogano modelli LLM di grandi dimensioni via API in cloud (come, ad esempio, GPT di OpenAI disponibile via servizi Azure di Microsoft),
- e dove è possibile, si possono anche usare Modelli open, magari anche “compatti” e “leggeri” per specifici compiti di processo attraverso specifici agenti LLM. E il caso, ad esempio, del Modulo Discriminator del “core” dei Servizi Humanativa per LLM prima illustrato, dove può essere usato un Modello Open per il suo specifico compito di instradamento della domanda verso la corretta pipeline.
Per chiudere, in Humanativa, come anticipato nel corso dell’articolo, ci siamo orientati fin dall’inizio a ideare una soluzione modulare e configurabile per servizi LLM. In linea concettuale, nonostante il nostro compito non sia di pubblicare paper, ci siamo riconosciuti anche rispetto agli studi e paper per ciò che sta accadendo per il RAG e la sua evoluzione verso approcci più modulari. Considerando sempre la “giovane età” del RAG e degli LLM è un buon riscontro per noi di Humanativa mostrarci in linea con le attuali tendenze anche verso i nostri Clienti.