
Come migliorare le capacità dell’LLM di generare risposte accurate in linguaggio naturale.
In questo ultimo anno, in cui i maggiori produttori di LLM proprietari e open-source hanno spinto verso una propria affermazione sul mercato, ci sono state voci pro e contro la “robustezza” ovvero della capacità dei Linguaggi LLM di rispondere in modo preciso senza finire nelle cosiddette “allucinazioni”.
Tutto questo ha portato sia i produttori di LLM che le Università a studiare tecniche per migliorare la capacità di generazione di risposte puntuali e precise. Tra queste, la tecnica del RAG (Retrieval-Augmented Generation) è la più affermata ed in continua evoluzione.
La tecnica del RAG
Viene considerata al momento dagli “addetti ai lavori” quasi una soluzione obbligata, in campo LLM, quando la base di conoscenza (Knowledge Base) è molto specifica e quindi difficilmente contestualizzabile dagli LLM costruiti per essere “generalizzati” e “multi-purpose”.
Al centro di questa tecnica tre step fondamentali che caratterizzano il cosiddetto RAG “Naive”:
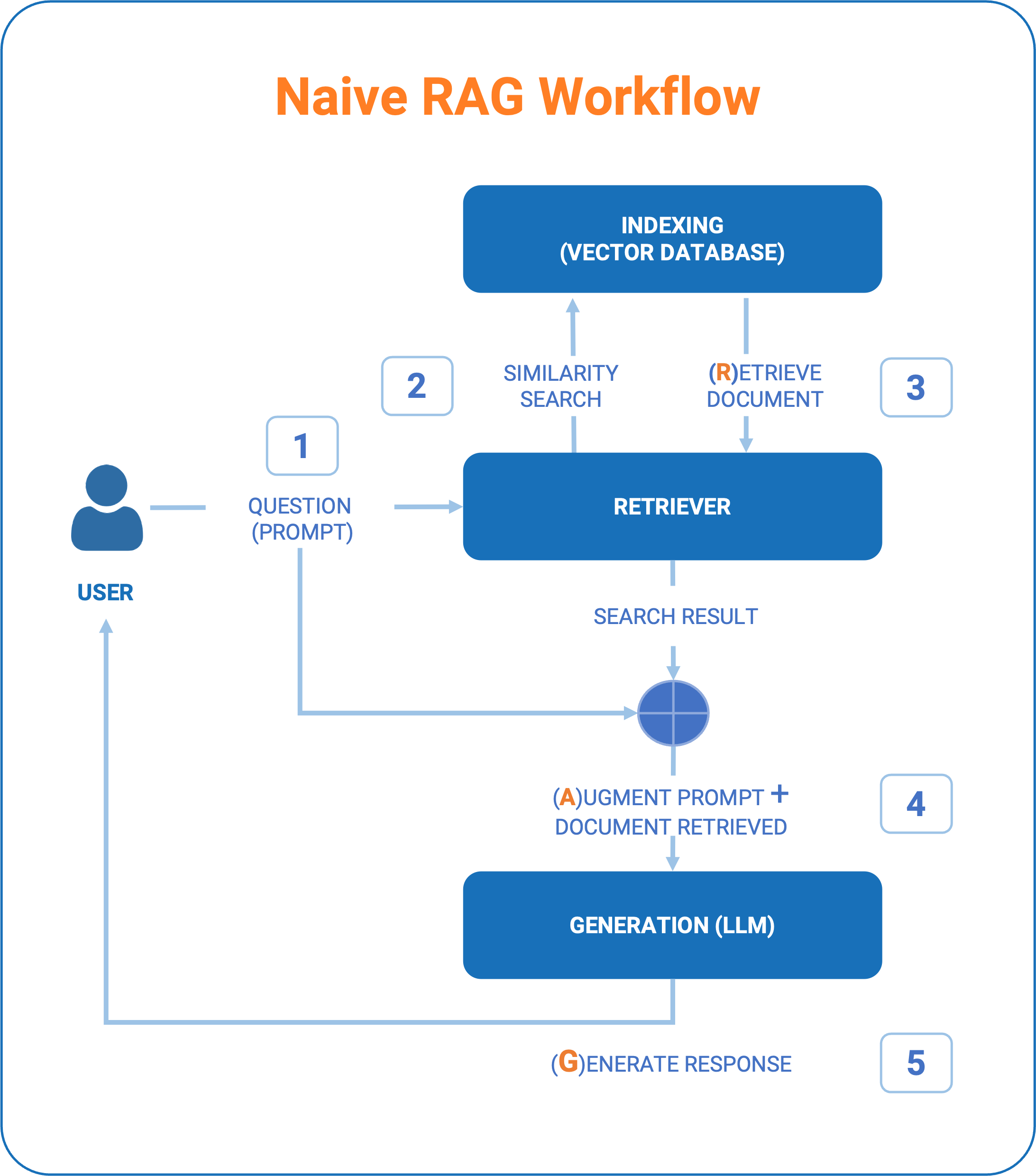
- Indexing: le informazioni (le chiameremo documenti) devono essere trasformate in una base di conoscenza “indicizzata”. Questa fase di inizializzazione e poi, nel tempo, di aggiornamento continuo della conoscenza è fondamentale per poi usare nella fase successiva di “retrieve” i metodi di interrogazione basati su criteri di “similarità”.
- Retrieve: prende in input la “domanda” dell’utente e ne recupera le informazioni più attendibili utilizzando uno o più algoritmi che consentono di individuare tra i documenti quelli che più si avvicinano ad una corretta definizione del “contesto” da fornire alla Generazione della risposta LLM.
- Generation: La generazione del risultato infine ha due peculiarità:
- una prima fase di prompt engineering in cui viene costruito il “vero” prompt verso il modello di AI. Potremmo definirlo come “augmented prompt” perchè unisce la domanda posta dall’utente, le informazioni di base reperite attraverso la retrieve, insieme a indicazioni al modello su come rispondere e che tipo di output ci si attende (formattazione, stile ecc…). L’ingegnerizzazione del Prompt costituisce quindi un punto cruciale da cui può dipendere la capacità di dare un buon risultato.
- Una seconda fase di interrogazione del modello LLM che termina con la generazione del testo di risposta basata sia sulla conoscenza del modello sia sulle informazioni recuperate.
In sintesi questa tecnica:
- Permette di utilizzare la potenza di calcolo dei grandi modelli LLM ma in funzione di un dominio molto verticale e specifico (“domain-specific”).
- Evita i costi di addestramento. In altre parole, costituisce una via per evitare di addestrare modelli LLM su uno specifico dominio di dati che avrebbe un costo esorbitante in risorse computazionali anche se si disponesse di un modello open-source.
- Offre una ampia aspettativa di miglioramento delle risposte dell’LLM poiché:
- offre la possibilità al modello LLM di avere un contesto “domain specific” in aggiunta per rispondere a domande che richiedono informazioni non contenute nei dati di addestramento del modello utilizzato.
- Può potenzialmente fornire risposte aggiornate su argomenti contenuti nella Knowledge base che in una azienda ad es. cambiano frequentemente.
- Aumentare la precisione delle risposte degli assistenti virtuali, motori di ricerca e altre applicazioni interattive.
RAG: nascita, adozione per gli LLM e la sua recente evoluzione
La tecnica è nata ufficialmente nel 2020 da Facebook AI Research (FAIR), e l’approccio iniziale era di combinare modelli di recupero con modelli generativi per migliorare le capacità dei modelli NLP in compiti che richiedevano conoscenze aggiornate e informazioni dettagliate, superando i limiti dei modelli di linguaggio statici. (rif. paper “Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks”, pubblicato da Patrick Lewis, Ethan Perez, Aleksandra Piktus, e altri ricercatori).
Ma nonostante la tecnica sia nata nel 2020, l’approccio RAG ha visto un’adozione significativa proprio dal 2023 in poi, soprattutto per gli LLM di nuova generazione dove al centro c’è la necessità di rispondere a domande complesse ma in modo contestuale, facendo uso di informazioni recuperate da conoscenza di dominio.

Quindi la tecnica RAG, nel campo LLM, potremmo dire che ha una “giovane età” e che dal 2023 ad oggi (fine 2025) aziende, università, papers si susseguono con molta velocità. Si è quindi passati da una tecnica RAG Naive, ad Advanced RAG fino al recente approccio modulare del Modular RAG. Quest’ultimo approccio, in continua evoluzione, è una raccolta di ulteriori task specializzati, sempre più specifici, per rendere il workflow dell’LLM (da domanda a risposta) sempre più robusto.
In questa terza specie della evoluzione si colloca anche la soluzione LLM di Humanativa, perché basata su una esperienza maturata su grandi progetti del 2024-2025 per diversi clienti che spiegheremo in un successivo articolo.
RAG e Fine Tuning – Tecniche a confronto
Per chiudere le argomentazioni legate al RAG e quindi alla possibilità di offrire una soluzione LLM che combini conoscenza “domain-specific” e risposte LLM accurate, c’è un ultimo aspetto del quale si parla molto nella community di Data Science ed è il confronto tra RAG e Fine-Tuning.
Quale di questi due approcci è il più utile? Dipende dal dato del dominio, come sempre.
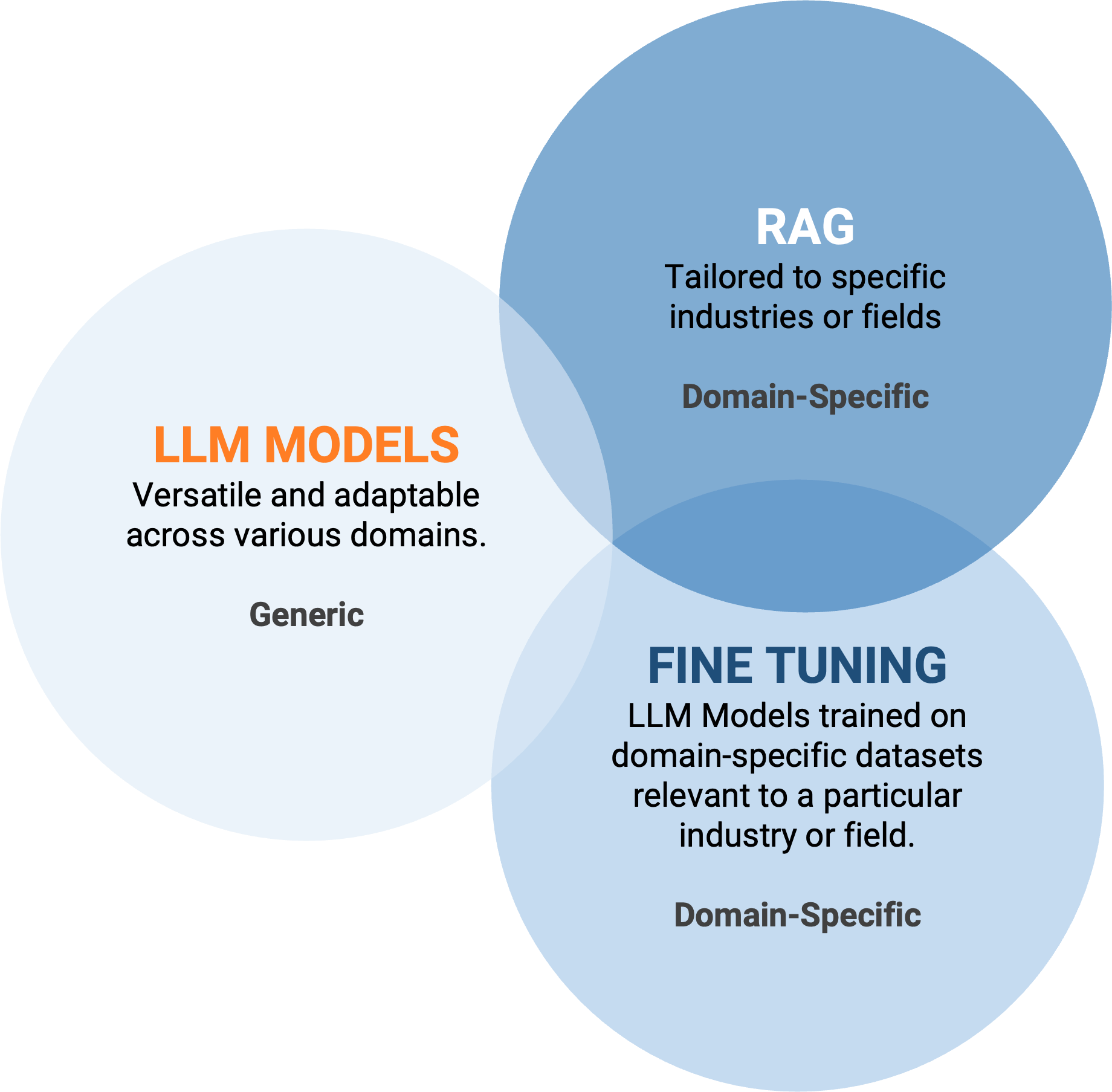
Il RAG è utile quando si è in grado di aumentare il prompt del LLM con dati dinamici che non sono noti ad un LLM già addestrato, come i dati di domini specifici, dati personali (dell’utente), dati in tempo reale, o informazioni di contesto utili per il prompt.
Il fine-tuning consente invece al modello di apprendere pattern stabili e ricorrenti. Tuttavia, poiché si basa su dataset statici, le informazioni apprese dal modello possono non essere aggiornate nel tempo, rendendo necessario un nuovo addestramento per mantenerne la rilevanza.
Su questo tema non basta ovviamente un paragrafo, ma è un punto fondamentale da considerare nell’approcciare la soluzione ideale per un determinato dominio in base alla sua “dinamicità” o presenza di pattern stabili e ricorrenti.
Nei prossimi articoli a seguire, esporremo un ulteriore focus sulla Data Preparation per il RAG (il cosiddetto Indexing), dove verrà esplorato, per la fase di pre-processing, l’utilizzo e l’applicabilità dei nuovi Modelli di Linguaggio Visivo (VLM) (modelli di intelligenza artificiale che combinano capacità di visione artificiale e di elaborazione del linguaggio naturale).